みなさんこんにちは!このブログでは主に
の4つのトピックについて発信しています。
今回の記事では時系列データの分析について扱います!
これまでの記事↗では、偽相関の危険性、定常性の確認、差分・トレンド除去・季節調整による定常化、さらに ARIMA / SARIMA や VAR といった時系列モデルまで学んできました。ここまでで、時系列分析に必要な主要な考え方はひと通り出そろいました。ただし実務では、それぞれの手法を個別に知っているだけでは十分ではありません。実際には、時系列データを受け取ったときに「まず何を見るべきか」「非定常っぽいときにすぐ差分を取ってよいのか」「季節性があるなら ARIMA と SARIMA のどちらを考えるべきか」「複数系列があるときにいつ VAR を持ち出すべきか」といった判断で迷いやすいからです。
そこで今回は、ここまで学んできた内容を単なる復習として並べ直すのではなく、実務での判断順序という形で整理します。前処理、モデル選択、評価、解釈という流れに沿って、「どの段階で何を確認し、どこで判断を分けるべきか」を見ていきます。
この記事を読むことで、
- 時系列データを受け取ったときに最初に何を見るべきか
- 定常化をどのような考え方で選べばよいか
- ARIMA / SARIMA / VAR をどう使い分けるべきか
- モデル適用後に何を確認しないと危険か
が整理でき、自分のデータに対してどこから分析を始めるべきかの見取り図を持てるはずです。
「時系列分析は学んできたけれど、実務では結局どこから考えればよいのか迷う」と感じたことがある人は、ぜひ最後まで読んでみてください。
- Abstract | 実務では「何を見るか」の順序が重要
- Introduction | 時系列分析を実務で使うときに何が難しいのか
- Background | 実務で迷いやすいポイントをどう整理するか
- Data | 今回扱う実データ
- Method | 実務での判断フロー
- Results | 実データで判断フローを確認する
- Discussion | 実務への示唆
- Conclusion | まとめ
- References | Pythonコードの全文
- 時系列分析シリーズ
Abstract | 実務では「何を見るか」の順序が重要
時系列分析では、モデルを当てる前に確認すべきことが多くあります。トレンドや季節性があるのか、非定常性をどう扱うべきか、単変量モデルで十分なのか、それとも複数系列を同時に見るべきなのか。実務では、こうした判断を曖昧なまま進めてしまうことで、誤った相関解釈や不自然なモデル選択につながることがあります。
本記事では、ここまでのシリーズで学んできた内容を踏まえ、時系列分析の実務でよくある課題を 前処理・モデル選択・評価・解釈 の観点から整理します。具体的には、時系列データを受け取ったときに最初に何を見るべきか、定常化をどのように選ぶべきか、ARIMA / SARIMA / VAR をどう使い分けるべきか、モデル適用後に何を確認すべきかを確認します。
本記事の狙いは、個別の手法の定義を覚え直すことではありません。
系列の構造と分析の目的に応じて、どの順序で判断すべきかを整理すること にあります。
👉 まとめると:
時系列分析で重要なのは、「どのモデルを知っているか」よりも、どの段階で何を確認し、どの判断を先に置くべきか を理解することです。
Introduction | 時系列分析を実務で使うときに何が難しいのか
第7回までの記事では、定常性の確認や定常化の方法などの前処理から、ARIMA / SARIMAによる単変量モデル、VAR による多変量モデルまで、時系列分析に必要な主要な考え方を順番に整理してきました。具体的には、
- 第1回:ランダムウォークが生む偽相関↗
- 第2回:ADF検定による定常性の確認↗
- 第3回:トレンドや季節性がある場合の考え方↗
- 第4回:差分、トレンド除去、季節調整といった定常化手法↗
- 第5回:株価・GDP・売上データに対する定常化手法の適用↗
- 第6回:ARIMA・SARIMAによる単変量時系列モデルの比較↗
- 第7回:実データの多変量時系列モデル化(VARの適用)↗
を順番に整理してきました。
ここまでで、非定常な系列をそのまま扱うのは危険であり、まず系列の性質を見極めて整える必要があること、そして整えた系列はモデル化してはじめて予測や構造理解に使えることが見えてきたと思います。今回は、その流れを受けて、時系列分析を実務で使うときに「どこから確認し、どの順序で判断を進めるべきか」を整理していきます。
1. ここまでのシリーズで見えてきた分析の基本的な流れ
ここまでの内容を大きくまとめると、時系列分析ではまず偽相関に注意し、系列が定常かどうかを確認し、必要に応じて定常化したうえで、はじめてモデル化を考える、という流れになります。さらに、対象が1系列なら ARIMA / SARIMA、複数系列の関係まで見たいなら VAR というように、問いに応じてモデルの候補も変わってきます。
つまり、これまでのシリーズで見てきたのは、個別の手法の名前だけではありません。
時系列データでは、系列の性質を確認してから分析の進め方(=分析戦略)を選ぶ必要がある、という基本的な考え方そのものです。
2. それでも実務では、どこから考えるべきかで迷いやすい
ただし実務では、各手法を個別に知っているだけでは、すぐに分析を進められるとは限りません。実際には、分析の出発点で迷うことが多いからです。
たとえば、時系列データを受け取ったときに、まず相関や回帰を見てよいのか、それとも先に系列の形を確認すべきなのか。非定常に見えるときに、すぐ差分を取るべきなのか、それともトレンドや季節性の有無を先に確認すべきなのか。さらに、予測したい対象が1系列なのか、複数系列の関係まで見たいのかによっても、選ぶべきモデルは変わってきます。
このように、実務で難しいのは「どのモデルを使うか」そのものよりも、どの順序で確認し、どこで判断を分けるか を見極めることです。
3. 今回は、実務での判断順序を整理する
そこで今回は、ここまで学んできた内容を単なる復習として並べ直すのではなく、実務での判断順序という形で整理します。
具体的には、まず系列の構造を確認し、必要に応じて定常性を確かめ、非定常性の原因に応じて前処理を選び、そのうえで ARIMA / SARIMA / VAR のようなモデル選択につなげる流れを確認します。さらに、モデルを当てた後も、残差や予測誤差、結果の解釈まで含めて確認すべきことを整理します。
本記事で重視したいのは、個別の手法を暗記することではありません。
系列の構造と分析の目的に応じて、分析の進め方を組み立てることです。
👉 まとめると:
今回のテーマは、「どのモデルが優れているか」を比べることではありません。
時系列分析を実務で使うときに、何をどの順序で考えるべきかを整理することです。
Background | 実務で迷いやすいポイントをどう整理するか
ここまでのシリーズでは、偽相関、定常性、定常化、ARIMA / SARIMA、VAR といった論点をそれぞれ順に見てきました。
ただし実務では、これらの問題が別々に現れるとは限りません。実際には、時系列データを受け取った時点で、前処理・モデル選択・評価・解釈に関する論点が同時に出てきます。
そのため重要なのは、個別の手法を思い出すことではなく、どの論点を先に確認し、どこで判断を切り替えるかを整理しておくことです。ここでは、その中でも特に迷いやすいポイントを確認しておきます。
1. 系列そのものの構造を確認する
実務で時系列データを受け取ると、まず相関係数や回帰分析を見たくなることがあります。
とくに、売上と広告費、需要と価格、アクセス数と売上のように、複数の系列が並んでいるときは、「まず関係を見てみよう」と考えやすい場面です。
ただし、時系列データではこの出発点が危険になることがあります。
第1回で見たように、独立な系列同士でもトレンドを共有していれば、見かけ上の相関が現れることがあるからです。つまり、相関があるように見えたとしても、それが本当に系列同士の関係を反映しているとは限りません。
このため、時系列分析では相関や回帰の前に、その系列がどのような構造を持っているかを確認する必要があります。
2. 非定常かどうか、その原因は何かを分けて考える
時系列データで次に起こりやすいのは、非定常性の確認を省略したまま分析を進めてしまうことです。
右肩上がりの売上系列や、季節変動を含む需要系列のように、実務データにはトレンドや季節性を含むものが多くあります。
こうした系列をそのまま回帰や予測モデルに入れると、モデルが系列の構造を正しく捉えているのか、それとも非定常な動きに引きずられているだけなのかが分かりにくくなります。結果として、見かけ上の当てはまりはよくても、解釈しにくいモデルや再現性の低い予測につながることがあります。
第2回から第5回までで見てきたように、時系列分析ではまず定常性を確認し、非定常であればその原因がトレンドなのか、季節性なのか、それ以外なのかを見極めることが出発点になります。
3. 問いに応じてモデル候補を絞る
時系列モデルを選ぶ場面では、「どのモデルが優れているか」という発想に引っ張られやすいことがあります。
しかし第6回、第7回で見たように、ARIMA / SARIMA / VAR は、それぞれ使う場面が異なります。
たとえば、1つの系列を予測したいなら ARIMA 系が候補になりますし、季節性が明確なら SARIMA を考える理由が出てきます。一方で、複数系列の相互関係やラグを含む影響まで見たいなら、VAR のような多変量モデルを検討することになります。
ここで大切なのは、モデルの複雑さや有名さではありません。
予測したいのか、関係を見たいのか、系列は1本か複数か、季節性はあるか といった問いに応じて、モデルの候補を絞ることです。
4. 結果の評価を精度だけで終わらせない
実務では、モデルを作ったあとに予測精度だけで採用を決めてしまうことがあります。
もちろん精度は重要ですが、それだけでは十分ではありません。
たとえば、残差に自己相関が残っていれば、系列の構造をまだ取り切れていない可能性があります。また、予測に使えるモデルであっても、そのまま因果的な説明に使えるとは限りません。さらに、少し精度が高いだけの複雑なモデルよりも、前提が明確で説明しやすいモデルの方が、実務で使いやすいこともあります。
そのため、時系列分析ではモデルを当てた後も、
- 残差に構造が残っていないか
- 時系列の順序を守った予測誤差になっているか
- その結果を何に使うのかが明確か
を確認する必要があります。
👉 まとめると:
実務で迷いやすいポイントは、個別の手法の定義が分からないことではありません。
相関を見る前に何を確認するか、非定常性をどう扱うか、どの問いにどのモデルを使うか、結果をどこまで業務判断に使うか を整理しないまま進めてしまうことです。
Data | 今回扱う実データ
今回は、時系列分析の実務で迷いやすいポイントを整理するために、3種類の実データを使います。
それぞれ、トレンドのある系列、季節性のある系列、複数系列を同時に見る例に対応しています。
1. トレンドのある系列:米国の実質GDP
トレンドを確認する例として、米国の実質GDPを使います。
用いるのは FRED で公開されている GDPC1 で、四半期ごとの実質GDP系列です。
この系列は、長期的な水準の変化を持つ代表的な時系列です。
そのため、
- まず系列をプロットしてトレンドの有無を確認する
- 非定常性を疑う
- 必要に応じて差分や成長率で見る
といった流れを確認するのに向いています。
2. 季節性のある系列:非季節調整の小売売上
季節性を確認する例として、米国の小売売上系列 RSAFSNA を使います。
これは FRED で公開されている月次の小売売上で、非季節調整系列です。
今回は、季節性を見落とさないことが主題なので、あえて季節調整済みではなく、元の季節変動を含んだ系列を使います。
この系列では、
- 周期的な変動が見えるか
- 自己相関や季節分解で季節性を確認できるか
- 季節差分や SARIMA を考えるべきか
といった点を見ていきます。
3. 複数系列の例:小売売上と広告・PR関連サービス収入
複数系列を同時に見る例として、小売売上 RSAFS と、広告・PR関連サービス収入 REV5418TMSA を使います。
前者は月次系列、後者は四半期系列なので、そのままでは比較しにくく、まず頻度を揃える必要があります。今回は小売売上を四半期に集約して、2系列を同じ頻度で扱います。
この例で確認したいのは、
- 複数系列があるときに、単変量モデルで足りるのか
- 2系列の関係を同時に見る必要があるのか
- VAR を検討する前に、頻度や系列の性質を揃える必要があるのか
という点です。
4. 今回のデータの用途
今回の目的は、これらのデータに対して最も高精度なモデルを作ることではありません。
それぞれの系列を見ながら、どのようなデータに対して、何を先に確認し、どのように分析方針を分けるべきかを整理することが目的です。
Method | 実務での判断フロー
ここでは、時系列データを実務で受け取ったときに、どのような順序で確認を進めるべきかを整理します。
重要なのは、最初からモデルを当てにいくことではありません。まず系列の形を確認し、非定常性の有無と原因を切り分け、そのうえで前処理とモデル選択につなげていくことです。
今回扱う実質GDP、小売売上、小売売上と広告・PR関連サービス収入の例も、この流れに沿って見ていきます。
1. まずプロットして、系列の構造を確認する
最初に行うべきなのは、系列をプロットして全体の形を見ることです。
ここで確認したいのは、たとえば次のような点です。
- 長期的な上昇や下降があるか
- 周期的な変動が見えるか
- 水準が途中で変わっていないか
- 外れ値や急な落ち込みがないか
- 欠損や異常な観測がないか
時系列分析では、相関係数や回帰係数より前に、系列そのものの形から得られる情報が多くあります。
たとえば実質GDPなら長期的な水準変化が見えるかどうか、小売売上なら年ごとの繰り返しが見えるかどうかを、まず視覚的に確認することが出発点になります。
2. 非定常性を疑ったら、検定で確認する
プロットからトレンドや持続的な変動が見えた場合は、次に定常性を確認します。
ここでは ADF 検定のような方法を使って、水準系列のままで扱ってよいかを確認します。
ただし、検定結果だけで判断を完結させるのではなく、
- プロットで何が見えているか
- 自己相関にどのような特徴があるか
- 検定結果がその観察と整合しているか
を合わせて考える必要があります。
たとえば実質GDPでは、系列を見た時点でトレンドが疑われます。その場合、ADF 検定は「その直感を統計的に確認する」ための手段として使うことになります。
小売売上でも、季節性やトレンドが混ざっていれば、水準系列のままでは扱いにくいことがあります。
3. 差分・トレンド除去・季節調整をどう選ぶか
非定常だからといって、すぐ一階差分を取ればよいとは限りません。
ここで必要なのは、何が非定常性の原因なのかを切り分けることです。
大きく分けると、次のような考え方になります。
- 長期トレンドが主な問題なら、差分や成長率で見る
- 時間に沿った傾向を分けて扱いたいなら、トレンド除去を考える
- 周期的な変動がはっきりしているなら、季節差分や季節調整を考える
- トレンドと季節性が両方あるなら、その両方を考慮する
たとえば非季節調整の小売売上では、年ごとの周期が見えるだけでなく、水準自体も変化していることがあります。その場合、「季節差分だけで十分か」「通常の差分も必要か」を確認しなければなりません。
ここで大切なのは、定常化を機械的な作業にしないことです。
差分を取ること自体が目的ではなく、後続の分析に使える系列に整えることが目的です。
4. 問いに応じてモデル候補を絞る
前処理を終えたあとで初めて、モデル候補を絞る段階に入ります。
ここで重要なのは、「どのモデルが高機能か」を考えることではなく、今回の問いに対して、どのモデルが必要かを考えることです。
判断の軸は、たとえば次の通りです。
- 予測したい対象は 1 系列か、複数系列か
- 季節性をモデル側で明示的に扱う必要があるか
- 複数系列のラグ関係まで見たいのか
- 単変量モデルで問いに十分答えられるか
対象が 1 系列で、季節性を特に持たないなら、非季節の ARIMA 系モデルが候補になります。
1 系列でも、月次小売売上のように季節構造が明確なら、SARIMA のように季節性を明示的に扱うモデルを候補に入れる必要があります。
一方で、複数系列の関係そのものを説明したいなら、VAR のような多変量モデルが候補になります。
つまり、ARIMA / SARIMA / VAR は優劣で並ぶものではありません。
問いが 1 系列の予測なのか、季節性を含む 1 系列の予測なのか、複数系列の関係を含むのかによって、候補が変わるということです。
5. モデル適用後に必ず確認したいこと
モデルを当てた後も、そこで終わりではありません。
少なくとも、次の点は確認しておく必要があります。
- 残差に自己相関が残っていないか
- 時系列の順序を守った予測誤差になっているか
- モデルの前提と結果の使い方が対応しているか
- 予測と因果を混同していないか
たとえば予測精度が高くても、残差に構造が残っていれば、系列の特徴をまだ取り切れていない可能性があります。
また、2系列を入れたモデルで予測上の関係が見えたとしても、それだけで因果的な解釈まで言えるわけではありません。
そのため、モデルの採否は精度だけで決めず、残差・前提・解釈・利用目的まで含めて判断する必要があります。
6. 今回の判断フローで見たいこと
以上をまとめると、実務での判断フローは次のようになります。
- まず系列をプロットして構造を見る
- 非定常性を疑ったら検定で確認する
- 原因に応じて前処理を選ぶ
- 問いに応じてモデル候補を絞る
- モデル適用後に残差と解釈を確認する
今回の記事では、このうちまず 1〜3 を実データで確認し、その結果を踏まえて 4〜5 を実務上の判断軸として整理していきます。
👉 まとめると:
時系列分析では、最初にモデルを選ぶのではありません。
系列の構造を確認し、非定常性の原因を切り分け、そのうえで問いに対応したモデル候補を絞り、最後に結果の評価まで行うことが基本になります。
Results | 実データで判断フローを確認する
ここでは、Method で整理した判断フローのうち、まず 系列の構造を確認すること、非定常性を検定で確かめること、前処理を選ぶこと の 3 点を実データで確認します。扱うのは、実質GDP、非季節調整の小売売上、小売売上と広告・PR関連サービス収入の 3 つの例です。今回の目的はモデルの優劣を比べることではなく、時系列データを前にしたときに、どこで何を確認し、どのように次の判断につなげるべきかを Python で実証することです。
1. 必要なライブラリと関数の準備
まずは、必要なライブラリと補助関数を準備します。
1.1 ライブラリのインポート
以下のようにライブラリをインポートしておきます。
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas_datareader.data import DataReader
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.tsa.api import VAR
plt.rcParams["figure.figsize"] = (10, 4)
plt.rcParams["font.size"] = 111.2 補助関数の準備
今回の実装では、FRED から系列を取得する関数、ADF 検定を行う関数、時系列をプロットする関数などをあらかじめ用意しておきます。
def download_fred_series(series_id: str, start: str, end: str) -> pd.Series:
"""
Download a FRED series and return it as a clean pandas Series.
"""
series = DataReader(series_id, "fred", start, end)[series_id].dropna()
series.name = series_id
return series
def plot_series(series: pd.Series, title: str, ylabel: str = "") -> None:
"""
Plot a single time series.
"""
fig, ax = plt.subplots()
series.plot(ax=ax)
ax.set_title(title)
ax.set_ylabel(ylabel)
ax.grid(alpha=0.3)
plt.show()
def plot_two_series(
original: pd.Series,
transformed: pd.Series,
title1: str,
title2: str,
ylabel1: str = "",
ylabel2: str = "",
) -> None:
"""
Plot an original series and a transformed series in two panels.
"""
fig, axes = plt.subplots(2, 1, figsize=(10, 7))
original.plot(ax=axes[0])
axes[0].set_title(title1)
axes[0].set_ylabel(ylabel1)
axes[0].grid(alpha=0.3)
transformed.plot(ax=axes[1])
axes[1].set_title(title2)
axes[1].set_ylabel(ylabel2)
axes[1].grid(alpha=0.3)
plt.tight_layout()
plt.show()
def plot_two_axis_series(
left_series: pd.Series,
right_series: pd.Series,
title: str,
left_ylabel: str = "",
right_ylabel: str = "",
left_color: str = "C0",
right_color: str = "C1",
log_left: bool = False,
log_right: bool = False,
) -> None:
"""
Plot two series on shared x-axis with separate left and right y-axes.
"""
fig, ax1 = plt.subplots(figsize=(10, 4))
ax2 = ax1.twinx()
left_series.plot(ax=ax1, color=left_color, label=left_series.name)
right_series.plot(ax=ax2, color=right_color, label=right_series.name)
if log_left:
ax1.set_yscale("log")
if log_right:
ax2.set_yscale("log")
ax1.set_title(title)
ax1.set_ylabel(left_ylabel, color=left_color)
ax2.set_ylabel(right_ylabel, color=right_color)
ax1.tick_params(axis="y", labelcolor=left_color)
ax2.tick_params(axis="y", labelcolor=right_color)
ax1.grid(alpha=0.3)
lines1, labels1 = ax1.get_legend_handles_labels()
lines2, labels2 = ax2.get_legend_handles_labels()
ax1.legend(lines1 + lines2, labels1 + labels2, loc="upper left")
plt.show()
def run_adf_test(series: pd.Series, label: str) -> pd.Series:
"""
Run the ADF test and return the main results as a pandas Series.
"""
s = series.dropna()
result = adfuller(s)
return pd.Series(
{
"series": label,
"test_statistic": result[0],
"p_value": result[1],
"n_lags": result[2],
"n_obs": result[3],
}
)
def make_monthly_profile(series: pd.Series) -> pd.DataFrame:
"""
Compute monthly mean values for a monthly time series.
"""
df = pd.DataFrame({"value": series.dropna()})
df["month"] = df.index.month
monthly_profile = df.groupby("month")["value"].mean().to_frame("monthly_mean")
return monthly_profile
def to_quarterly_sum(series: pd.Series, anchor_month: int = 1) -> pd.Series:
"""
Convert a monthly series to quarterly sums and label each quarter
by the specified anchor month.
Parameters
----------
series : pd.Series
Monthly time series with a DatetimeIndex.
anchor_month : int, default 1
Month used as the quarter label.
- 1: Jan / Apr / Jul / Oct
- 2: Feb / May / Aug / Nov
- 3: Mar / Jun / Sep / Dec
"""
if anchor_month not in [1, 2, 3]:
raise ValueError("anchor_month must be one of {1, 2, 3}")
s = series.dropna().copy()
quarter_period = s.index.to_period("Q")
quarterly = s.groupby(quarter_period).sum()
quarter_start = quarterly.index.start_time
if anchor_month == 1:
new_index = quarter_start
elif anchor_month == 2:
new_index = quarter_start + pd.DateOffset(months=1)
else:
new_index = quarter_start + pd.DateOffset(months=2)
quarterly.index = pd.DatetimeIndex(new_index)
quarterly.name = series.name
return quarterly以上の準備をもとに、まずは各系列を実際にプロットして、どのような構造を持っているかを確認します。
2. 系列をプロットして、構造を確認
時系列分析では、最初にモデルを選ぶのではなく、系列そのものの形を確認することが重要です。
ここでは、実質GDP、非季節調整の小売売上、小売売上と広告・PR関連サービス収入の 3 つの例を使って、プロットからどのような手がかりが得られるかを見ていきます。
2.1 実質GDPをプロットする
まず、実質GDP系列 GDPC1 を取得してプロットします。
# download real GDP
gdp = download_fred_series("GDPC1", start="2000-01-01", end="2025-12-31")
# plot original GDP
plot_series(
gdp,
title="US Real GDP (GDPC1)",
ylabel="Billions of Chained 2017 Dollars"
)実行すると、下図1が表示されます。
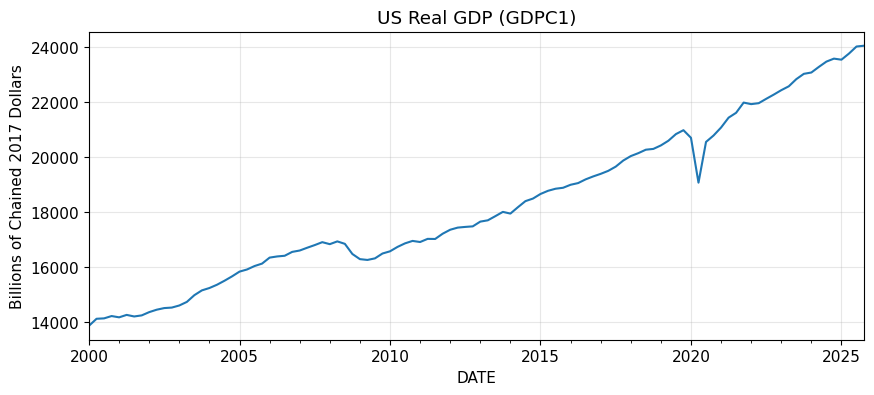
図1からは、系列全体に長期的な上昇傾向があることが確認できます。
2008 年前後や 2020 年前後には一時的な落ち込みもありますが、全体として見ると水準が時間とともに変化しています。
ここで重要なのは、GDP が増えていることそのものではなく、平均のまわりで安定に揺れている系列ではなさそうだと分かることです。
この段階で、まずトレンドと非定常性を疑うべき系列だと判断できます。
2.2 非季節調整の小売売上をプロットする
次に、非季節調整の小売売上 RSAFSNA を取得してプロットします。
# Download not-seasonally-adjusted retail sales data
retail_na = download_fred_series("RSAFSNA", start="2010-01-01", end="2025-12-31")
retail_na.head()
# Plot the original retail sales series
plot_series(
retail_na,
title="US Retail Sales, Not Seasonally Adjusted (RSAFSNA)",
ylabel="Millions of Dollars"
)実行すると、下図2が表示されます。
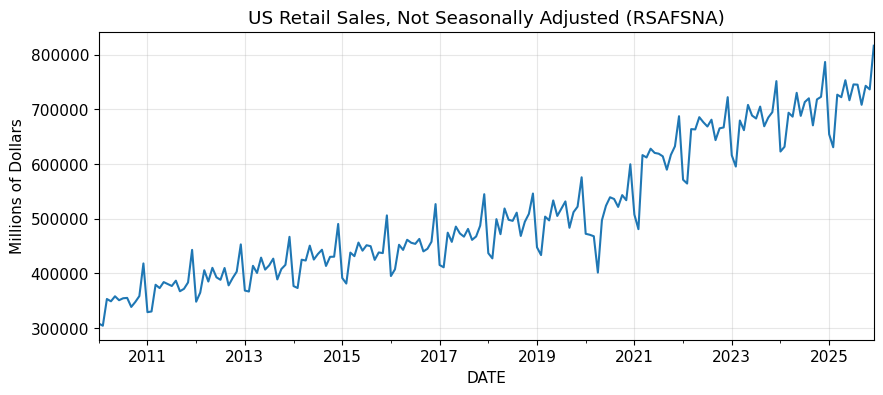
この系列では、長期的な水準変化だけでなく、年ごとに似たタイミングで山と谷が繰り返されていることが見て取れます。
とくに年末付近で水準が上がり、その後に落ち込むパターンが何度も現れています。
この時点で分かるのは、「変動が大きい」ということではありません。
周期的な変動を先に疑うべき系列だということです。したがって、この系列では通常の差分だけを考えるのではなく、季節性を別に確認する必要があります。
2.3 小売売上と広告・PR関連サービス収入をプロットする
最後に、小売売上 RSAFS と広告・PR関連サービス収入 REV5418TMSA を確認します。
ここで最初に注意すべきなのは、小売売上は月次系列、広告・PR関連サービス収入は四半期系列であり、そのままでは並べて比較できないことです。
データダウンロード
まずはデータをダウンロードして確認します。
# Download seasonally adjusted retail sales and ad-related revenue data
retail_sa = download_fred_series("RSAFS", start="2003-01-01", end="2025-12-31")
ad_rev = download_fred_series("REV5418TMSA", start="2003-01-01", end="2025-12-31")
# Check first a few records
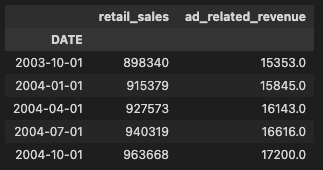
retail_sa.head(), ad_rev.head()実行すると、下記のように表示されます。2つのデータの頻度が月次と四半期次で整合していないことがわかります。
(DATE
2003-01-01 288657
2003-02-01 284696
2003-03-01 288177
2003-04-01 289053
2003-05-01 289619
Name: RSAFS, dtype: int64,
DATE
2003-10-01 15353
2004-01-01 15845
2004-04-01 16143
2004-07-01 16616
2004-10-01 17200
Name: REV5418TMSA, dtype: int64)データの頻度調整・結合
次に、小売売上を四半期合計に変換し、同じ頻度で扱えるようにします。今回は四半期の売上規模を見たいので平均ではなく合計を取り、広告・PR関連サービス収入の四半期系列と同じ頻度で比較できるようにします。
# Convert monthly retail sales to quarterly sums and align the two series
retail_q = to_quarterly_sum(retail_sa, anchor_month=1)
retail_q.name = "RSAFS_quarterly_sum"
# Join two data sets
df_var = pd.concat([retail_q, ad_rev], axis=1).dropna()
df_var.columns = ["retail_sales", "ad_related_revenue"]
# Check records
df_var.head()上記を実行すると、下図3が表示されます。
時系列データのプロット
この 2 系列を左右別軸でプロットします。
# Plot the aligned quarterly series with separate left and right y-axes
plot_two_axis_series(
left_series=df_var["retail_sales"],
right_series=df_var["ad_related_revenue"],
title="Quarterly retail sales and ad-related revenue",
left_ylabel="Retail sales",
right_ylabel="Ad-related revenue"
)上記を実行すると、下図4が表示されます。
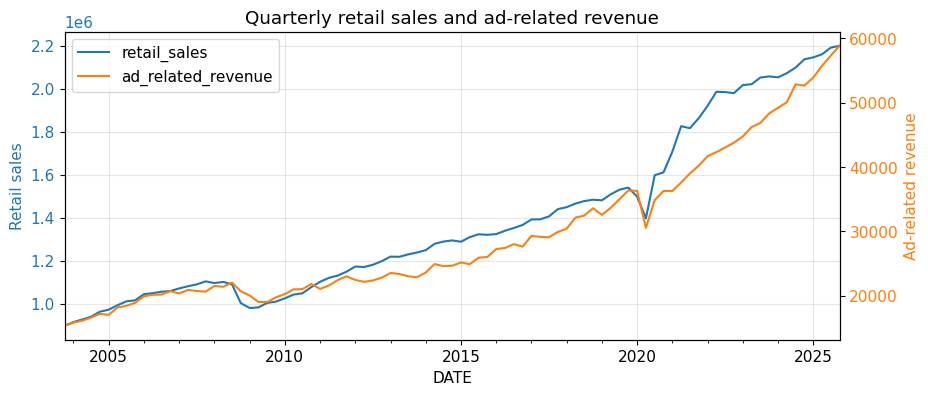
この図からは、両系列とも長期的には増加方向に動いていることが分かります。
ただし、この段階で「2 系列には強い関係がある」と結論づけるのは適切ではありません。どちらも水準が時間とともに変化する非定常系列である疑いが強く、似たトレンドを共有しているだけかもしれません。
現時点で分かるのは、
- まず頻度をそろえなければ比較できなかったこと
- どちらも水準が時間とともに変化していること
- 見た目の連動だけでは、関係の有無を判断できないこと
の 3 点です。
2.4 プロットから確認できたこと | 3つの系列の構造と論点
ここまでのプロットだけでも、3 つの系列で最初に考えるべき論点が異なることが分かります。
- 実質GDPでは、まずトレンドと非定常性を疑う
- 非季節調整の小売売上では、季節性を先に疑う
- 小売売上と広告・PR関連サービス収入では、頻度をそろえたうえで、水準系列のまま読んでよいかを確認する
つまり、時系列分析の出発点は「どのモデルを使うか」ではありません。
系列を実際に描いてみて、何が問題になりそうかを見分けることが最初の判断になります。
3. 非定常性を疑ったら、検定で確認する
前節では、プロットから
- 実質GDPには長期トレンドがありそうである
- 非季節調整の小売売上には季節性と水準変化がありそうである
- 小売売上と広告・PR関連サービス収入は、見た目に似た動きをしていても、そのまま関係を読めるとは限らない
ことを確認しました。
ただし、プロットだけでは「非定常らしい」という印象を持つところまでしか進めません。
そこで次に、ADF 検定を使って、水準系列のままで扱ってよいかを確認します。
ADF 検定では、帰無仮説は「単位根を持つ、すなわち非定常である」です。
したがって、p 値が十分に小さくならなければ、水準系列のままで扱うのは難しいと考えます。
3.1 実質GDPの ADF 検定
まず、実質GDP系列 GDPC1 に対して ADF 検定を行います。
# Run the ADF test on the original GDP series
run_adf_test(gdp, label="GDPC1 level")上記の実行結果は以下のようになります。
series GDPC1 level
test_statistic 1.011839
p_value 0.994389
n_lags 1
n_obs 102
dtype: objectこの結果では、p 値は 0.994 でした。
したがって、実質GDPの水準系列については、非定常性を棄却できません。
これは、前節のプロットで見た長期トレンドと整合的です。
つまり、実質GDPは水準系列のまま扱うのではなく、差分や成長率への変換を検討すべき系列だと分かります。
3.2 非季節調整の小売売上の ADF 検定
次に、非季節調整の小売売上 RSAFSNA に対して ADF 検定を行います。
# Run the ADF test on the original sales series
run_adf_test(retail_na, label="RSAFSNA level")上記を実行すると、以下のようになります。
series RSAFSNA level
test_statistic 0.78193
p_value 0.991339
n_lags 15
n_obs 176
dtype: objectこの結果では、p 値は 0.991 でした。
したがって、この系列も水準のままでは非定常性を棄却できません。
ここで重要なのは、小売売上の非定常性は、GDP と同じ形ではない可能性が高いことです。
GDP では主に長期トレンドが問題になっていましたが、小売売上ではそれに加えて季節性も含まれています。したがって、この系列では単に「非定常である」と確認するだけでなく、その原因がトレンドなのか、季節性なのか、あるいは両方なのかを切り分ける必要があります。
3.3 小売売上と広告・PR関連サービス収入の ADF 検定
最後に、四半期にそろえた小売売上 retail_sales と広告・PR関連サービス収入 ad_related_revenue の 2 系列に対して、ADF 検定を行います。
# Check stationarity of the level series
adf_var_level = pd.DataFrame(
[
run_adf_test(df_var["retail_sales"], label="retail_sales level"),
run_adf_test(df_var["ad_related_revenue"], label="ad_related_revenue level"),
]
)
# see result
adf_var_level上記を実行すると、下図5のような結果となります。

結果は次の通りでした。
retail_salesの p 値:0.997ad_related_revenueの p 値:1.000
どちらの系列も、水準のままでは非定常性が非常に強いことが分かります。
この点は、複数系列を扱うときに特に重要です。
前節のプロットでは 2 系列が似た動きをしているように見えましたが、ここで両系列とも非定常だと確認された以上、見た目の連動をそのまま系列間の関係として読んではいけないことが分かります。
3.4 ADF 検定から確認できたこと
ここまでの結果を整理すると、3つの例はいずれも水準系列のままでは扱いにくいことが分かりました。
- 実質GDP: トレンドの強い非定常系列であることが確認された
- 非季節調整の小売売上: トレンドだけでなく季節性も含んだ非定常系列である可能性が高い
- 小売売上と広告・PR関連サービス収入: 両系列とも非定常であり、水準同士の見た目の連動はそのまま解釈できない
つまり、前節のプロットで抱いた疑いは、ADF 検定でも裏づけられました。
次に考えるべきなのは、それぞれの系列に対して、どの前処理を選ぶべきかという点です。
4. 定常化の処理(差分・季節差分・頻度調整)をどう選ぶか
前節では、3つの例のいずれも水準系列のままでは扱いにくいことを確認しました。
ただし、ここで重要なのは「非定常なら一階差分を取る」と機械的に決めないことです。時系列データでは、何が非定常性の原因なのかによって、選ぶべき前処理が変わります。
ここでは、各系列に対して実際に変換を加え、どのような前処理が有効そうかを確認します。
4.1 実質GDPでは、対数差分で変化率に注目する
まず、実質GDPについては、長期トレンドが強いことがすでに分かっています。
GDP のように水準が大きく、長期的に増加する系列では、単純差分よりも対数差分の方が変化率として解釈しやすくなります。そこで、ここでは対数差分を用います。
対数差分系列の作成
まずは対数差分系列を作成します。
# Compute log differences to approximate growth rates
gdp_log = np.log(gdp)
gdp_log_diff = gdp_log.diff().dropna()
# Check records
gdp_log_diff.head()実行すると、以下のように対数差分系列の最初の数行が表示されます。
DATE
2000-04-01 0.018049
2000-07-01 0.001019
2000-10-01 0.005953
2001-01-01 -0.003283
2001-04-01 0.006226
Name: GDPC1, dtype: float64プロットして確認
対数差分化した系列をプロットして確認します。
# Compare the original GDP series and the log-differenced series
plot_two_series(
original=gdp,
transformed=gdp_log_diff,
title1="US Real GDP level",
title2="US Real GDP log difference",
ylabel1="Level",
ylabel2="Log difference"
)実行すると、下図6が表示されます。
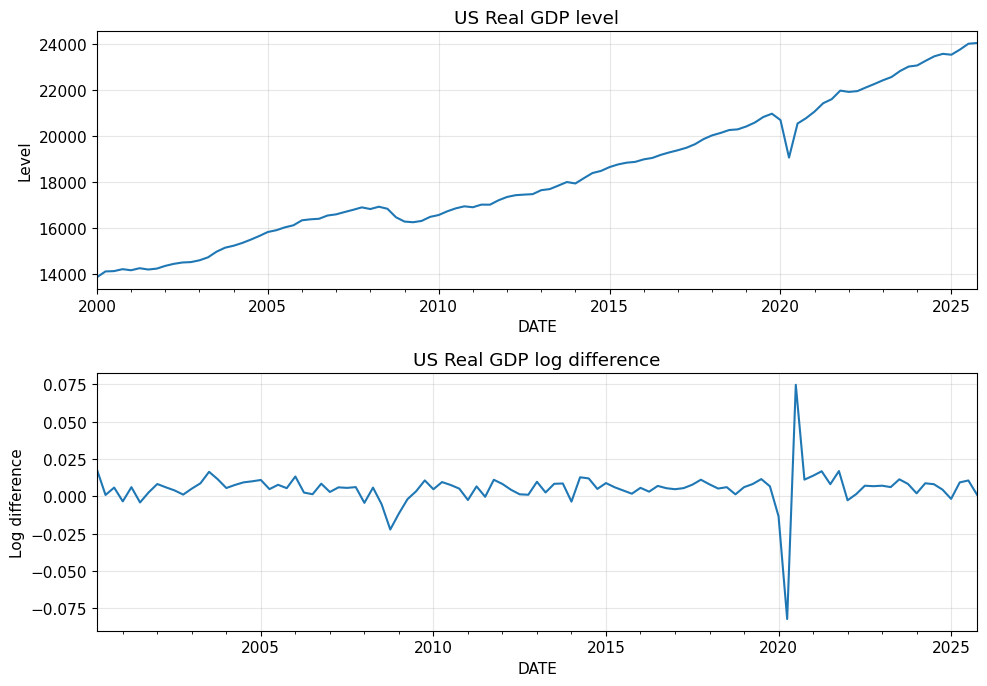
図6の対数差分後の系列を見ると、水準系列で見えていた長期的な上昇はかなり弱まり、短期的な変動が中心に見えるようになります。
対数差分系列のADF検定
続いて、変換後の系列に対して ADF 検定を行います。
# Run the ADF test on the log-differenced GDP series
run_adf_test(gdp_log_diff, label="GDPC1 log diff")実行すると、下記のように表示されます。
series GDPC1 log diff
test_statistic -12.14638
p_value 0.0
n_lags 0
n_obs 102
dtype: objectこの結果では、p 値は ほぼ 0 となりました。
したがって、実質GDPについては、水準系列のまま扱うのではなく、対数差分によって成長率ベースの系列に変換することが有力な前処理だと分かります。
4.2 小売売上では、一階差分だけでなく季節差分も比較する
次に、非季節調整の小売売上 RSAFSNA を考えます。
この系列では、
- 水準系列のままでは非定常であること
- 年ごとに繰り返される季節パターンがありそうなこと
を確認しました。したがって、ここでは一階差分だけでなく、季節差分も比較する必要があります。
季節差分を含めた差分系列の作成・プロット
一階差分、12か月の季節差分、一階差分と季節差分を組み合わせた系列を作り、プロットして確認します。
# Get differenced series for comparison
retail_na_diff1 = retail_na.diff().dropna()
retail_na_diff12 = retail_na.diff(12).dropna()
retail_na_diff1_diff12 = retail_na.diff().diff(12).dropna()
# plot differeced series
plot_two_series(
original=retail_na,
transformed=retail_na_diff1_diff12,
title1="RSAFSNA level",
title2="RSAFSNA diff(1) + diff(12)",
ylabel1="Level",
ylabel2="Differenced"
)実行すると、下図7が表示されます。
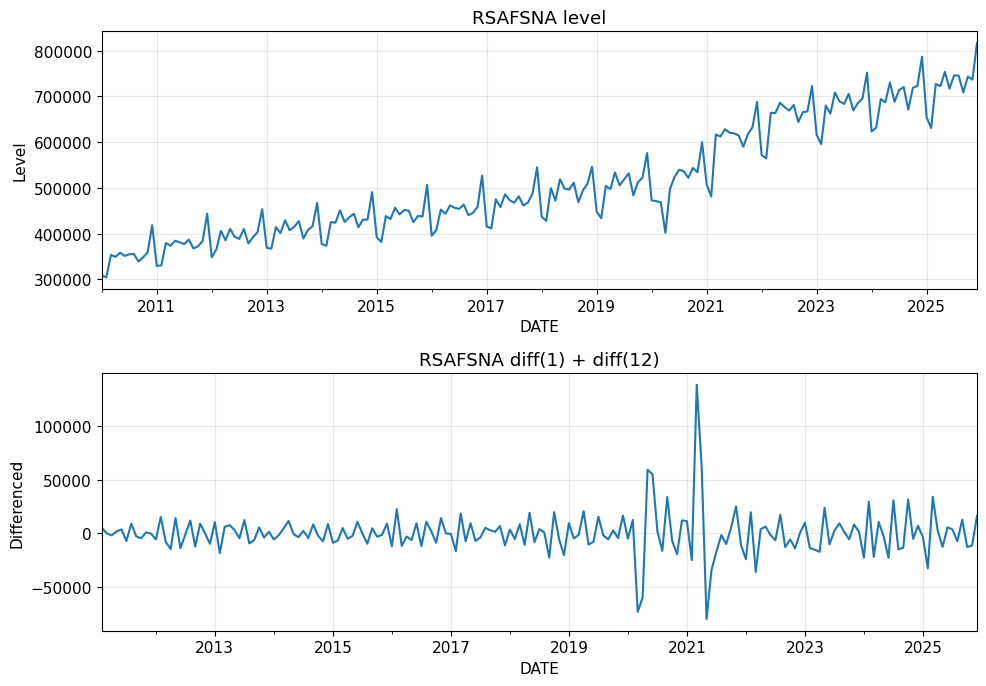
図7では代表として、一階差分と季節差分を組み合わせた系列を原系列と比較しています。
変換後の系列では、水準の上昇傾向や季節的な大きな振れがかなり弱まり、原系列とは見え方が大きく変わります。
それぞれの差分系列のADF検定
次に、各変換に対する ADF 検定の結果を比較します。
# Compare ADF results across multiple transformations
adf_retail = pd.DataFrame(
[
run_adf_test(retail_na, label="RSAFSNA level"),
run_adf_test(retail_na_diff1, label="RSAFSNA diff(1)"),
run_adf_test(retail_na_diff12, label="RSAFSNA diff(12)"),
run_adf_test(retail_na_diff1_diff12, label="RSAFSNA diff(1)+diff(12)"),
]
)
adf_retail実行すると、下図8が表示されます。
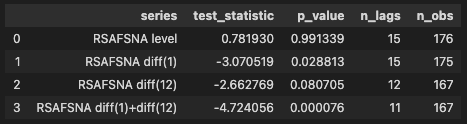
結果は次のようになりました。
- 水準系列:p 値 0.991
- 一階差分:p 値 0.029
- 12か月差分:p 値 0.081
- 一階差分 + 12か月差分:p 値 0.000076
この結果から分かるのは、小売売上では一階差分だけでも一定の改善は見られるものの、それだけで十分とは言い切れないことです。
また、季節差分だけでも非定常性を弱められますが、最もはっきり改善したのは、一階差分と季節差分を組み合わせた場合でした。
つまり、この系列では トレンド由来の非定常性 と 季節性由来の非定常性 の両方を考える必要があると分かります。
4.3 複数系列では、まず頻度をそろえてから対数差分を取る
最後に、小売売上 RSAFS と広告・PR関連サービス収入 REV5418TMSA の 2 系列について確認します。
この例では、前処理に入る前にすでに 1 つ重要な操作がありました。それが頻度をそろえることです。小売売上は月次系列なので、四半期系列と比較するには集約が必要でした。
対数差分系列の作成
小売売上、広告・PR関連サービス収入の両系列とも水準のままでは非定常性が強かったため、対数差分を取ります。
# Take log differences to focus on growth-type movements
df_var_log = np.log(df_var)
df_var_diff = df_var_log.diff().dropna()
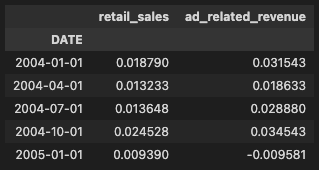
df_var_diff.head()実行すると、下図9が表示されます。
プロットして確認
対数差分化した系列の推移をプロットして確認します。
# Plot the log-differenced multivariate series
plot_two_axis_series(
left_series=df_var_diff["retail_sales"],
right_series=df_var_diff["ad_related_revenue"],
title="Log-differenced quarterly retail sales and ad-related revenue",
left_ylabel="Retail sales log diff",
right_ylabel="Ad-related revenue log diff"
)実行すると、下図10が表示されます。
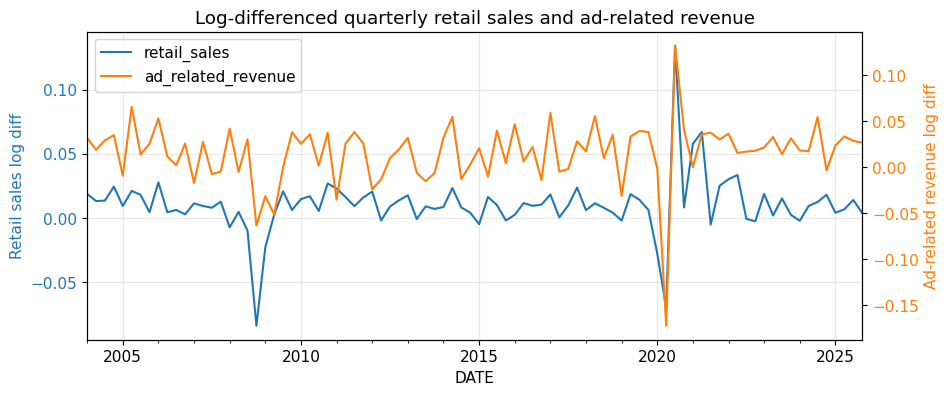
変換後の系列をプロットすると、原系列で見えていた長期的な上昇は弱まり、変動の比較がしやすくなります。
対数差分系列のADF検定
対数差分後の系列に対して ADF 検定を行います。
# Check stationarity after log differencing
adf_var_diff = pd.DataFrame(
[
run_adf_test(df_var_diff["retail_sales"], label="retail_sales log diff"),
run_adf_test(df_var_diff["ad_related_revenue"], label="ad_related_revenue log diff"),
]
)
adf_var_diff実行結果は下図11です。

結果は次の通りでした。
retail_salesの p 値:2.17×10\(^{-15}\)ad_related_revenueの p 値:6.31×1\(^{-20}\)
どちらの系列も、対数差分後には定常性の観点でかなり扱いやすくなっています。
この例では、「非定常だから差分を取る」というだけでなく、複数系列を同時に扱う前に、頻度をそろえるという前処理が必要だったことが重要です。
4.4 前処理の比較から確認できたこと
ここまでの結果から、前処理は一律ではなく、系列の性質に応じて選ぶ必要があることが分かりました。
- 実質GDP: 対数差分による変換が有効
- 小売売上: 一階差分だけでなく季節差分も比較する必要があった
- 複数系列: 差分の前にまず頻度をそろえる必要があった
つまり、時系列分析では、系列の構造を見て、何が問題なのかを切り分けたうえで前処理を選ぶことが出発点になります。
Discussion | 実務への示唆
ここまでの Results では、実質GDP、小売売上、複数系列の例を使って、系列の構造、非定常性、その原因に応じた前処理の違いを確認しました。
ここではその結果を踏まえて、実務ではどのようにモデル候補を絞るべきか、またモデルを当てた後に何を確認しないと危険かを整理します。
1. 問いに応じてモデル候補を絞る
モデル候補は、系列の数や流行りの手法で決めるものではありません。
まず考えるべきなのは、何を知りたいのかです。
1つの系列だけを予測したいのであれば、単変量モデルが出発点になります。
そのうえで、季節性が明確でなければ ARIMA 系、季節性を明示的に扱う必要があれば SARIMA 系、というように候補を絞っていくのが自然です。
一方で、複数系列の関係そのものを見たいのであれば、多変量モデルが候補になります。
ただし、複数系列が手元にあることと、複数系列を同時に扱うべきことは同じではありません。重要なのは、その問いが複数系列を必要としているかです。
つまり、モデル選択の順序は
- まず問いを確認する
- 次に系列の構造を確認する
- そのうえで必要なモデル候補を絞る
という形になるべきです。
2. モデル適用後に確認しないと危険なこと
モデルを当てた後も、そこで終わりではありません。
実務で特に危険なのは、精度だけで採否を決めてしまうことです。
確認すべきなのは、少なくとも次の3点です。
- 残差に構造が残っていないか
- 予測誤差が時系列の順序を守った評価になっているか
- モデルの結果をどこまで解釈してよいか
たとえば、予測精度が高くても、残差に自己相関が残っていれば、系列の特徴をまだ取り切れていない可能性があります。
また、複数系列を入れたモデルで関係が見えたとしても、それだけで因果的な説明まで言えるわけではありません。
実務では、当たるかどうか と その結果をどう使ってよいか を分けて考える必要があります。
3. 実務ではモデル選択より前の判断が重要
今回の結果を通して見えてきたのは、時系列分析ではモデル選択より前の判断が重要だということです。
- 系列を見て、何が起きているかを確認する
- 非定常かどうかを確かめる
- その原因に応じて前処理を選ぶ
- その後で、問いに応じてモデル候補を絞る
- 最後に、残差や解釈まで含めて評価する
この順序を飛ばして最初からモデルを選ぶと、見かけ上はうまくいっても、後で解釈や説明の段階で無理が出やすくなります。
つまり、時系列分析で本当に重要なのは、モデル名をたくさん知っていることではありません。
系列の構造、分析の問い、結果の使い方をつなげて判断できることです。
Conclusion | まとめ
今回は、時系列分析を実務で進めるときの判断順序を整理しました。
重要なのは、最初からモデルを選ぶことではなく、まず系列の構造を確認し、非定常性の有無とその原因を見極め、そのうえで前処理とモデル候補を考えることです。
実際に確認したように、実質GDPではトレンドが主な論点になり、小売売上では季節性も含めて考える必要がありました。また、複数系列を扱う場合には、差分の前に頻度をそろえる必要があることも分かりました。つまり、時系列分析では「非定常なら差分」「複数系列なら VAR」のように機械的に進めることはできません。系列の性質に応じて、どの処理が必要かを判断することが出発点になります。
さらに、モデル候補は系列の数だけで決まるものではなく、何を知りたいのかという問いに応じて絞る必要があります。加えて、モデルを当てた後も、精度だけで終わらせず、残差や解釈可能性、結果の使い方まで含めて確認しなければなりません。
要するに、時系列分析で大切なのは、モデル名を覚えることではなく、系列の構造、分析の問い、結果の利用目的をつなげて判断することです。
次回予告
次回は、このシリーズ全体の内容を振り返りながら、偽相関から定常化、モデル選択までを一つの流れとして整理します。
ここまで学んできた各回の役割をつなぎ直し、時系列分析の全体像を改めて確認していきます。
References | Pythonコードの全文
今回の記事で書いたPythonコード(Jupyter Notebook)の全文は以下です。ご参考にどうぞ!

コメント