みなさんこんにちは!このブログでは主に
の4つのトピックについて発信しています。
今回の記事では時系列データの分析について扱います!
これまでの記事では、時系列データの分析における「偽物の相関」の危険性↗や、定常性の確認↗・非定常性の性質↗、そして定常化の代表的な方法↗について学んできました。
今回はいよいよ 実データを用いたケーススタディ に入ります。
株価、GDP、売上データといった実務でよく登場する時系列データを例に、実際にPythonで非定常性を確認し、差分・トレンド除去・季節調整といった処理を適用していきます。
👉 この記事を読むことで、
- 実データで「非定常性」がどのように現れるか
- 適切な前処理を施すことで「定常化」できること
- Pythonでの実装方法と検定の確認手順
が理解でき、読者のみなさんが自分のデータに応用できるイメージを持てるはずです。
Abstract | 実データで定常化を確認する
時系列データの分析において、非定常性を無視してしまうと「偽物の相関」や誤った結論につながるリスクがあります。
本記事では、株価・GDP・売上データという代表的な時系列を例に、Pythonを使って以下を実証します。
- 非定常データをそのまま扱うとどうなるか
- 差分・トレンド除去・季節調整によって定常化できるか
- ADF検定を用いて処理前後の違いを検証
結果、いずれのケースでも「処理前は非定常 → 処理後は定常」と判定されることを確認します。
この記事を読めば、実務で直面する時系列データに対して、適切に定常化を行う具体的な方法を理解できるようになります。
Background | 前回までのおさらい
これまでのシリーズでは、時系列データを扱う際に避けては通れない「定常性」について、基礎から実証まで解説してきました。
- 第1回:「偽物の相関」のリスクを実証↗
- ランダムウォークを例に、無関係なデータ同士でも76%の確率で相関が「有意」と誤判定されることを確認しました。
- 第2回:ADF検定による定常性の確認↗
- ランダム変数(ホワイトノイズ)は定常と判定され、ランダムウォークは非定常と判定されることをPythonで実証しました。
- 第3回:非定常性の原因を整理↗
- トレンド項や時間項を含むデータでは、定数周りでは非定常と判定されても、トレンド周りや時間項周りでは定常とみなせる場合があることを確認しました。
- 第4回:定常化の代表的な方法を学ぶ↗
- 差分、トレンド除去、季節調整、ARIMAの4つの手法をPythonで実装し、どのように非定常データを定常化できるかを整理しました。
これらを踏まえて、今回の第5回では 実データに実際に適用してみる ことを目的とします。
理論とシミュレーションで学んだ知識を、株価やGDP、売上データといった実務的な時系列に当てはめ、どのように定常性を確認・処理していくかを実証していきます。
Data | ケーススタディの対象データ
今回のケーススタディでは、実務でよく登場する3種類の時系列データを取り上げ、Pythonで実際に取得・分析を行います。
それぞれに異なる特徴があり、非定常性の性質も異なるため、定常化の手法を検証するには格好の教材となります。
1. 株価データ(例:S&P500 日次株価)
全体像
- 特徴:ランダムウォーク性が非常に強く、非定常データの典型例
- 課題:そのままでは定常とは判定されず、差分(リターン)を取る必要がある
- 実務的背景:投資やリスク管理では、株価水準そのものよりも「リターン系列」を分析対象にすることが一般的。その背景には、差分を取ることで定常性が得られるという統計的性質があります
今回使用するデータ
- データソース:
yfinance(Yahoo Finance API) - 対象:S&P500 インデックス
- 期間:過去10年分(日次)
2. GDPデータ(米国四半期GDP)
全体像
- 特徴:長期的に右肩上がりのトレンドを持つ
- 課題:水準値は非定常と判定されるが、トレンド除去や成長率(差分系列)を取ると定常に近づく
- 実務的背景:景気循環や政策効果を分析する際には、トレンドに埋もれた短期的な変動を抽出する必要があります。そのため、GDP成長率やトレンド除去後の残差が分析対象となります
今回使用するデータ
- データソース:
pandas_datareader(FRED: 米国連邦準備銀行のデータベース) - 対象:米国GDP(四半期データ、実質系列)
- 期間:2010年〜現在
3. 小売売上データ(米国小売売上高:月次)
全体像
- 特徴:長期的な成長トレンドに加えて、年末商戦など強い季節性が存在
- 課題:トレンド除去だけでは定常化できず、季節調整を併用する必要がある
- 実務的背景:小売・観光・サービス産業では、需要予測や在庫管理のために、トレンドと季節性を切り分けて分析することが不可欠です
今回使用するデータ
- データソース:
pandas_datareader(FRED: 米国連邦準備銀行のデータベース) - 対象:米国小売売上高(Retail Sales, 月次)
- 期間:2010年〜現在
👉 このように、株価・GDP・小売売上の3つは、それぞれ「ランダムウォーク」「トレンド」「季節性」という異なる非定常性を代表しています。
次章の Method | 定常性の確認手法 では、それぞれに適した前処理をどのように行うのかを整理します。
Method | 定常性の確認手法
今回取り上げる株価・GDP・小売売上データは、それぞれ異なる形で非定常性を含んでいます。
そのため、データの性質に応じた前処理 を施し、定常性を確認する必要があります。ここでは代表的な3つの手法を整理します。
差分(Differencing)
- 考え方:系列の隣接する値の差を取ることで、ランダムウォークのような非定常性を取り除く
- 数式:一次差分は \(\Delta x_t = x_t – x_{t-1}\)
- 適用場面:株価データのようにランダムウォーク性が強い系列
- ポイント:一次差分で足りない場合は二次差分(\(\Delta^2 x_t = (x_t – x_{t-1}) – (x_{t-1} – x_{t-2})\))を適用することもある
トレンド除去(Detrending)
- 考え方:系列に含まれる線形トレンドを取り除き、残差を分析対象にする
- 方法:単回帰(例:\(x_t = a + bt + \epsilon_t\))でフィットし、残差\(\epsilon_t\)を使う
- 適用場面:GDPのように長期的に増加する傾向を持つ系列
- ポイント:トレンド除去によって短期的な循環やショックが見やすくなる
季節調整(Seasonal Adjustment)
- 考え方:周期的に繰り返されるパターン(例:年末商戦)を取り除き、系列を安定化させる
- 方法:移動平均法や
statsmodelsのseasonal_decomposeを使ってトレンド・季節・残差に分解 - 適用場面:売上データのように強い季節性を持つ系列
- ポイント:季節要因を取り除くことで、基調的な動きを把握できる
ADF検定による確認
- 考え方:処理前後の系列に対してADF検定を行い、定常性を統計的に確認する
- 帰無仮説:単位根あり(非定常)
- 対立仮説:単位根なし(定常)
- 判定基準:p値 < 0.05 なら定常とみなす
- ポイント:差分やトレンド除去、季節調整を行った後に、必ず検定で確認することが重要
👉 ここまでで、対象データに対して「どんな方法を適用し、どう確認するのか」が整理できました。
次の Result | Pythonによる実装と検証 では、実際にコードを動かし、処理前後での変化を図表と検定結果で確認していきます。
Result | Pythonによる実装と検証
ここからは、実際にPythonを使って株価・GDP・小売売上データを取得し、差分・トレンド除去・季節調整を適用して、処理前後で定常性が改善されるかを検証します。
分析の流れは共通しており、
- データの取得と可視化
- 前処理(差分・トレンド除去・季節調整など)
- ADF検定による定常性の確認
を順に行います。
準備 | 共通関数の定義
まずはプロットとADF検定を毎回簡単に呼び出せるように、前回記事↗と同じように共通関数を定義しておきます。
ライブラリーインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import adfuller
import statsmodels.api as sm
from statsmodels.tsa.seasonal import seasonal_decompose
import yfinance as yf
import pandas_datareader.data as webプロット関数
def plot_series(original, transformed, labels, titles):
"""
Plot original and transformed time series.
"""
fig, axs = plt.subplots(2, 1, figsize=(10, 6))
axs[0].plot(original, label=labels[0])
axs[0].set_title(titles[0])
axs[0].legend()
axs[1].plot(transformed, label=labels[1], color="orange")
axs[1].set_title(titles[1])
axs[1].legend()
plt.tight_layout()
plt.show()ADF検定関数
def run_adf_test(series, label):
"""
Run ADF test and print p-value.
"""
result = adfuller(series)
print(f"ADF Test ({label}): p-value = {result[1]:.4f}")
return result[1]
1. 株価データ(S&P500 日次株価)|差分による定常化
まずは、ランダムウォーク的な性質を持つ代表例として、S&P500の日次株価を扱います。
株価の水準系列は、一般に平均や分散が一定とはみなしにくく、非定常系列の典型例です。
そこで、前回学んだ 一次差分 を適用し、定常化できるかを確認します。
Pythonによる実装
S&P500の日次データを取得し、一次差分を計算します。
# Fetch S&P500 daily data
ticker = "^GSPC"
df = yf.download(
ticker,
start="2014-12-31",
end="2025-01-01",
interval="1d",
auto_adjust=True,
progress=False
)
# Extract close price series
sp500 = df["Close"].dropna()
# Apply first differencing
sp500_diff = sp500.diff().dropna()ここでは auto_adjust=True を指定しているため、株価系列は分割や配当の影響を調整したものになっています。
実務でも、こうした調整後系列を使うほうが扱いやすい場面が多いです。
続いて、元の系列と差分系列を上下2段のプロットで比較します。
# Plot original and differenced series
plot_series(
original=sp500,
transformed=sp500_diff,
labels=["S&P500 Close", "First Difference"],
titles=["Non-stationary series (S&P500 Close)", "After Differencing"]
)最後に、元系列と差分系列それぞれにADF検定を適用します。
# Run ADF tests
p1 = run_adf_test(sp500, "S&P500 Close")
p2 = run_adf_test(sp500_diff, "First Difference")時系列プロットの様子
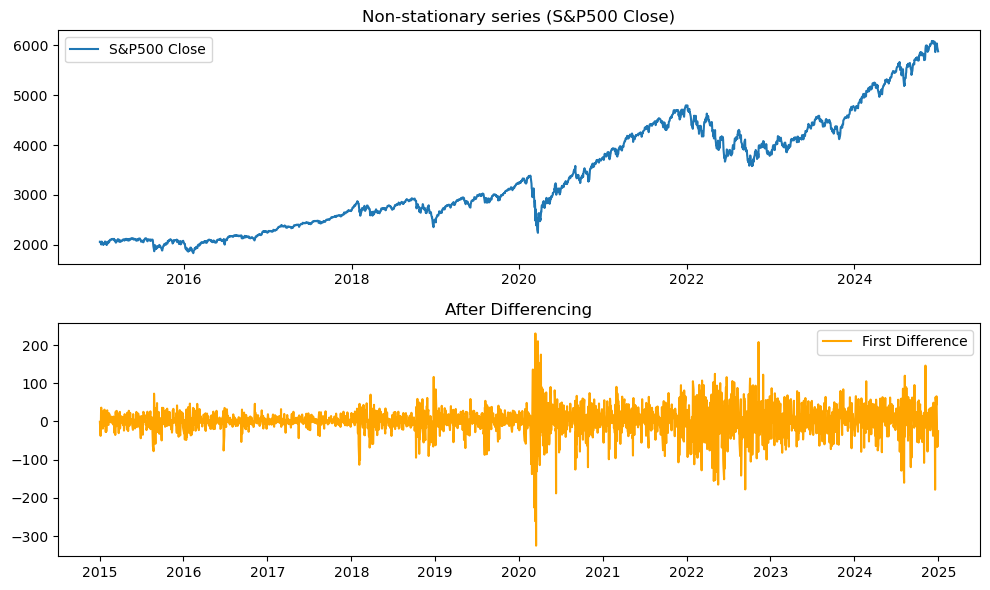
プロットの結果は下図1のように、上段にS&P500の終値系列、下段にその一次差分系列が表示されます。
上段の株価系列は、長期的な上昇傾向を持ち、平均が一定のまわりで上下しているようには見えません。
一方、下段の差分系列は、0付近を中心として変動するノイズ的な系列に近づいており、見た目にも定常化されたことがわかります。
ADF検定の結果
ADF検定の結果は、例えば次のようになります。
ADF Test (S&P500 Close): p-value = 0.9827
ADF Test (First Difference): p-value = 0.0000元系列では p値 > 0.05 となり非定常、
トレンド除去後系列では p値 < 0.05 となり定常と判定されます。
結果の解釈
結果を見ると、
- 元のS&P500終値系列は p値 > 0.05 となり、非定常と判定される
- 一次差分系列は p値 < 0.05 となり、定常と判定される
ことが確認できます。
これは、株価がランダムウォーク的に振る舞う系列であり、水準そのものを直接分析するのではなく、変化量に変換して扱うべき ことを意味します。
実務で株価そのものではなく、日次リターンや対数リターンを分析対象にすることが多いのも、この性質によるものです。
👉 このように、差分化はランダムウォーク型の非定常系列に対する基本的かつ有効な定常化手法であることが、実データでも確認できました。
2. GDPデータ|トレンド除去による定常化
次に、長期的なトレンドを持つ代表例として、米国の四半期GDPを扱います。
GDPのようなマクロ経済系列は、時間とともに右肩上がりに推移することが多く、そのままでは平均が一定とはみなせません。
そこでここでは、時間に対する単回帰でトレンドを推定し、その残差を取り出すことで、定常化できるかを確認します。
ただし、ここで重要なのは、どの期間を切り出すかによって結果が変わることです。
長い期間をまとめて扱うと、景気後退局面や構造変化の影響で、単純な線形トレンドでは捉えきれない場合があります。
今回はその点を踏まえ、2010年以降のGDP系列を用いて検証します。
Pythonによる実装
まずはFREDから米国の実質GDP系列を取得します。
ここでは、単回帰によるトレンド除去が機能しやすい 2010年以降 のデータに絞ります。
# Fetch quarterly real GDP data from FRED
gdp = web.DataReader("GDPC1", "fred", start="2010-01-01", end="2026-01-01")["GDPC1"].dropna()続いて、時間 index を説明変数にした単回帰を行い、線形トレンドを除去します。
# Create time trend
t = np.arange(len(gdp))
# Fit linear trend model
X = sm.add_constant(t)
model = sm.OLS(gdp, X).fit()
# Extract detrended series (residuals)
gdp_detrended = pd.Series(model.resid, index=gdp.index)そのうえで、元系列とトレンド除去後の系列を上下2段で比較します。
# Plot original and detrended series
plot_series(
original=gdp,
transformed=gdp_detrended,
labels=["Real GDP", "Detrended GDP"],
titles=["Non-stationary series (Real GDP)", "After Detrending"]
)最後に、元系列とトレンド除去後系列の両方にADF検定を適用します。
# Run ADF tests
p1 = run_adf_test(gdp, "Real GDP")
p2 = run_adf_test(gdp_detrended, "Detrended GDP")時系列プロットの様子
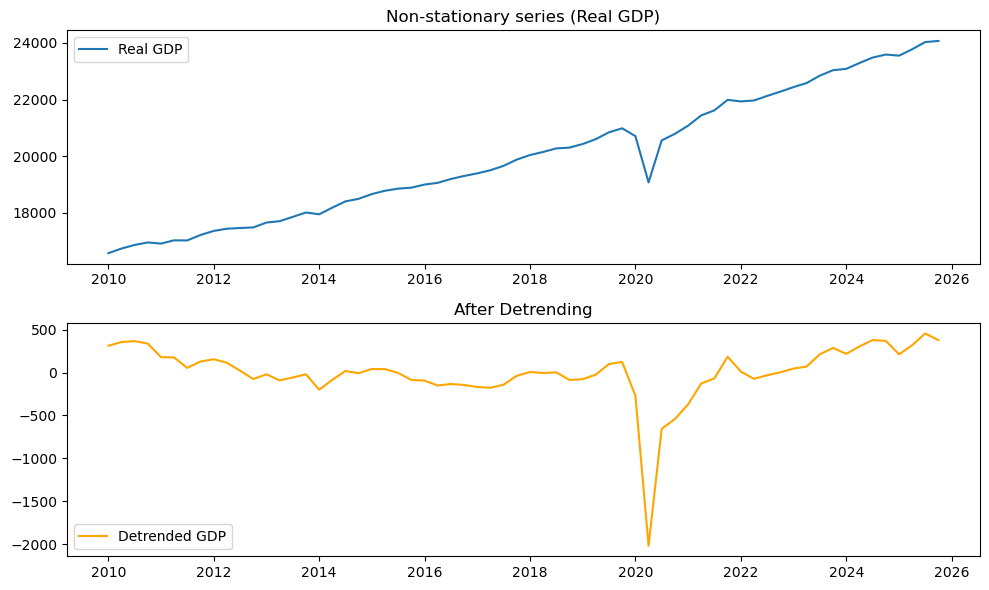
時系列プロットの結果は下図2のようになります。上段のGDP系列は、2010年以降に限って見ても、全体として右肩上がりのトレンドを持っています。
そのため、水準系列のままでは平均が一定とは言えず、非定常とみなすのが自然です。
一方、下段のトレンド除去後系列では、長期的な上昇傾向が取り除かれ、ゼロ付近で上下する系列が得られます。
2020年ごろにはコロナ禍による大きな一時的変動が見られますが、トレンドそのものが大きく折れ曲がっているわけではないため、2010年以降の期間では単回帰によるデトレンドが比較的うまく機能します。
ADF検定の結果
ADF検定の結果は、例えば次のようになります。
ADF Test (Real GDP): p-value = 0.9862
ADF Test (Detrended GDP): p-value = 0.0020元系列では p値 > 0.05 となり非定常、
トレンド除去後系列では p値 < 0.05 となり定常と判定されます。
結果の解釈
この結果から、2010年以降のGDP系列については、非定常性の主因が線形トレンドであり、そのトレンドを除去することで定常系列に近づけられることが確認できます。
ただし、ここで大事なのは、この結果は分析期間に依存するということです。
実際、2000年以降のGDP系列を使うと、2008–2009年のリーマンショックによる大きな落ち込みが含まれるため、単回帰による一本の直線では全体の動きを十分に表現できません。
その場合、デトレンド後の残差に非定常性が残り、ADF検定でも定常と判定されにくくなります。
つまり、GDPのようなマクロ系列では、
- トレンド除去をすればいつでも定常化できるわけではない
- 景気後退や構造変化をまたぐ期間では、単純な線形トレンドでは不十分なことがある
- 期間を限定する、構造変化を考慮する、あるいは差分系列やより柔軟なトレンドモデルを使う、といった工夫が必要になる
ということです。
実務でも、GDP水準をそのまま扱うのではなく、成長率やトレンド除去後の残差を分析対象にしますが、その前提として「どの期間ならその処理が妥当か」を確認することが欠かせません。
👉 このケースからわかるのは、トレンド除去は有効な定常化手法だが、ショックや構造変化をまたぐと単純な線形回帰だけでは足りないことがある、という点です。
3. 小売売上データ|季節調整による定常化
最後に、強い季節性を持つ代表例として、米国の小売売上データを扱います。
小売売上は、年末商戦や季節イベントの影響を受けやすく、毎年ほぼ同じ時期に似たパターンが繰り返されます。こうした系列は、そのままでは季節要因が大きすぎて、基調的な変動やショックを見誤りやすくなります。FRED の RETAILSMNSA は月次・未季節調整の系列なので、この目的に適しています。
ここでは、株価やGDPと同じく
- データ取得
- 定常化処理
- 図示で比較
- ADF検定
の順に確認します。
Pythonによる実装
まず、FREDから小売売上の未季節調整系列を取得します。
# Fetch monthly retail sales data from FRED
retail = web.DataReader("RETAILSMNSA", "fred", start="2010-01-01", end="2026-01-01")["RETAILSMNSA"].dropna()続いて、12か月周期を指定して季節分解を行います。月次データなので、周期は 12 です。
# Apply seasonal decomposition
decomp = seasonal_decompose(retail, model="additive", period=12)
# Extract seasonally adjusted residual series
retail_adjusted = decomp.resid.dropna()ここでは seasonal_decompose により、系列を trend・seasonal・residual に分解しています。
そのうえで、季節性を取り除いた後の系列として、ここでは residual を分析対象にしています。seasonal_decompose は単純な分解法であり、statsmodels でもより高度な手法として STL などが案内されていますが、今回は「季節要因を分離する」という考え方をつかむことを優先して、この方法を使います。
そのうえで、元系列と季節調整後系列を上下2段で比較します。
# Plot original and seasonally adjusted series
plot_series(
original=retail,
transformed=retail_adjusted,
labels=["Retail Sales (NSA)", "Seasonally Adjusted Residual"],
titles=["Non-stationary series (Retail Sales)", "After Seasonal Adjustment"]
)最後に、元系列と季節調整後系列の両方にADF検定を適用します。
# Run ADF tests
p1 = run_adf_test(retail, "Retail Sales (NSA)")
p2 = run_adf_test(retail_adjusted, "Seasonally Adjusted Residual")時系列プロットの様子
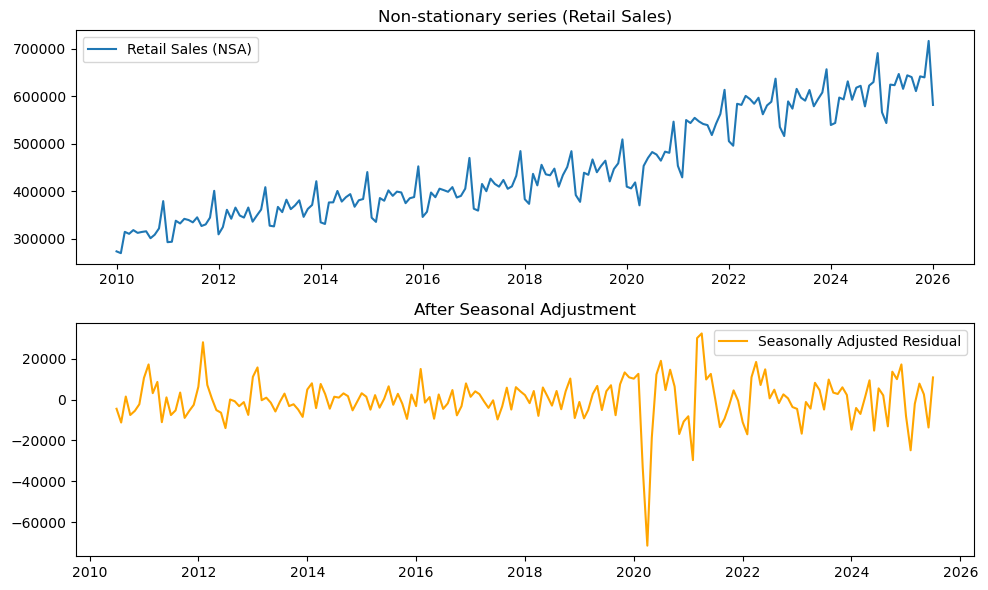
時系列プロットの結果は下図3のようになります。上段の元系列を見ると、毎年ほぼ同じ時期に山と谷が現れ、強い季節性があることがわかります。特に年末に大きく伸びるパターンが繰り返されており、季節要因が系列全体を大きく支配しています。FRED の RETAILSMNSA 自体が未季節調整系列なので、このような周期性がそのまま残っています。
一方、下段の季節調整後系列では、その規則的な年周期の揺れがかなり弱まり、季節変動に隠れていた短期的な上下が見やすくなります。
このケースでは、単に「売上が増えた・減った」を見るのではなく、その変化が季節要因なのか、それともそれ以外のショックなのか を切り分けることが重要です。
ADF検定の結果
ADF検定の結果は、例えば次のようになります。
ADF Test (Retail Sales (NSA)): p-value = 0.9841
ADF Test (Seasonally Adjusted Residual): p-value = 0.0000元系列では p値 > 0.05 となり非定常、
季節調整後系列では p値 < 0.05 となり定常と判定されます。
結果の解釈
この結果から、小売売上のような季節性の強い系列では、そのまま分析すると毎年繰り返される季節パターンに引っ張られ、真に見たい変動を捉えにくいことがわかります。
そこで、季節成分を切り分けたうえで残差系列を見ることで、より安定した系列として扱いやすくなります。
ここで注意したいのは、今回使った seasonal_decompose は 単純な分解法だという点です。実務では、より滑らかで頑健な分解が必要な場合に STL などを使うこともあります。とはいえ、「まずは季節性を疑い、周期を指定して分解し、処理前後でADF検定を比べる」という流れ自体は、とても実践的です。
👉 このように、季節調整は、周期的な揺れが強い時系列に対して有効な定常化の入口になります。
需要予測や売上分析の場面では、まず季節性を取り除いてから、トレンドや外生ショックを評価する、という順番が重要です。
Discussion | 実務への示唆
ここまで、株価・GDP・小売売上という3種類の実データに対して、
それぞれ
- 差分
- トレンド除去
- 季節調整
という異なる定常化手法を適用してきました。
この結果からわかるのは、「非定常ならとりあえず差分を取ればよい」わけではない、ということです。
大事なのは、データに含まれている非定常性の原因を見極め、それに対応した前処理を選ぶことです。
非定常性には「種類」がある
今回の3つのケースは、それぞれ異なる種類の非定常性を持っていました。
- 株価:ランダムウォーク的な変動
- GDP:長期的な上昇トレンド
- 小売売上:周期的な季節性
見た目としてはどれも「そのままでは安定していない系列」に見えますが、
中身は同じではありません。
そのため、同じ前処理を一律に当てても、うまく定常化できるとは限りません。
たとえばGDPのケースでは、単回帰によるトレンド除去が有効でしたが、
それは 2010年以降という比較的素直な期間に限定した場合 でした。
2008–2009年のような大きな景気後退をまたぐと、一本の直線で全体を説明するのは難しくなります。
つまり実務では、
「どの手法を使うか」だけでなく、「どの期間を分析対象にするか」も同じくらい重要 です。
まず見るべきは、p値ではなく系列の形
ADF検定は非常に便利ですが、実務では 最初にp値だけを見る のは危険です。
今回も、各ケースでまず系列を図示し、そのうえでADF検定を行いました。
この順番が大切なのは、ADF検定が「なぜ非定常なのか」までは教えてくれないからです。
p値が大きかったとしても、その原因が
- トレンドなのか
- 季節性なのか
- ランダムウォークなのか
- 構造変化なのか
は、グラフを見ないと判断できません。
実務で時系列データを受け取ったときには、いきなりモデルを当てるのではなく、
- まず時系列プロットを見る
- 非定常性の原因を仮説として持つ
- その仮説に合った前処理を試す
- 最後にADF検定で確認する
という順番で進めるのが安全です。
「定常化」は分析前の下ごしらえである
定常化は、それ自体が目的ではありません。
本来の目的は、その先にある
- 回帰分析
- ARIMAなどの時系列モデル
- 相関分析
- 因果推論や施策評価
を、誤った前提なしに行える状態に整えることです。
非定常な系列をそのまま使うと、第1回で見たように、
本当は関係のない系列どうしに強い相関があるように見えてしまうことがあります。
これは、統計的にはもっともらしい結果が出ていても、
意思決定に使うと危険な典型例です。
実務では「モデルが回るかどうか」よりも、
その結果を意思決定に使ってよいかどうか のほうが重要です。
その意味で、定常化は単なる前処理ではなく、
分析結果を判断に使える形に整えるための前提条件 と言えます。
一度の処理で終わるとは限らない
今回の記事では、それぞれ代表的な1手法を使いましたが、
実際のデータでは、1回の処理だけで十分とは限りません。
たとえば、
- 差分を取ってもまだトレンドが残る
- 季節調整をしてもレベルシフトが残る
- 構造変化が大きく、期間を分ける必要がある
といったことは、実務では珍しくありません。
そのため、実際の分析では
- 差分
- 対数変換
- トレンド除去
- 季節調整
- 期間の分割
- 外れ値やショックの確認
を組み合わせながら、何度か試行錯誤することになります。
重要なのは、
「正しい手法を最初から一発で当てること」ではなく、系列の性質を見ながら妥当な処理を絞り込んでいくこと です。
実務での使い分けの目安
今回の内容を、実務上の感覚としてまとめると、次のようになります。
- 水準がふらふら歩くように動いている
→ まず差分を疑う - 長期的に右肩上がり・右肩下がり
→ まずトレンド除去や成長率を疑う - 一定周期で山と谷が繰り返される
→ まず季節調整を疑う
もちろん現実のデータは、これらが一つだけとは限りません。
トレンドと季節性を同時に持つ系列もあれば、
ショックで途中から性質が変わる系列もあります。
だからこそ、
「このデータは何が原因で非定常なのか?」を先に考えること が、
時系列分析の出発点になります。
Conclusion | まとめと次回予告
今回は、これまで学んできた定常性と定常化の考え方を、
実際のデータに適用して確認しました。
扱ったのは、次の3種類の時系列です。
- 株価データ:差分による定常化
- GDPデータ:トレンド除去による定常化
- 小売売上データ:季節調整による定常化
それぞれ、非定常性の原因は異なっていました。
株価はランダムウォーク的な動き、GDPは長期トレンド、小売売上は季節性が支配的でした。
そして、その原因に応じた前処理を行うことで、処理後の系列がより安定し、ADF検定でも定常と判定されることを確認しました。
ここで重要なのは、定常化は機械的に行うものではないという点です。
まず系列を見て、何が非定常性の原因なのかを考え、それに応じた方法を選ぶ。
そのうえで、処理後の系列をもう一度図示し、ADF検定で確認する。
この流れこそが、実務で時系列データを扱うときの基本になります。
また、GDPの例で見たように、
同じ手法でも分析期間によって結果が変わることがあります。
つまり、前処理の選択だけでなく、「どの期間を分析対象にするか」も重要です。
時系列分析では、データ全体を一括で処理するのではなく、
構造変化や大きなショックの有無を意識しながら扱う必要があります。
今回の記事を通じて、
- 非定常データをそのまま使う危険性
- 非定常性の原因に応じて前処理を選ぶ重要性
- Pythonで定常化とADF検定を実行する基本の流れ
が、より具体的にイメージできるようになったのではないでしょうか。
次回予告
次回は、こうして定常化した系列を使って、
実際に時系列モデルを当てるステップ に進みます。
定常化はあくまでスタート地点です。
その先で、どのようにモデル化し、予測や解釈につなげるのかを見ていきましょう。
References | Pythonコードの全文
今回の記事で書いたPythonコード(Jupyter Notebook)の全文は以下です。ご参考にどうぞ!
コメント