
Ciao!みなさんこんにちは!このブログでは主に
(1)pythonデータ解析,
(2)DTM音楽作成,
(3)お料理,
(4)博士転職
の4つのトピックについて発信しています。
今回は統計学&pythonレシピです!
本シリーズでは、任意の確率分布から任意の個数のランダムサンプルを得る方法をご紹介しています!
シリーズ第2回(前回)と第3回(今回)では、そのための2つの手法
- 棄却サンプリング (rejection sampling)
- MHサンプリング (Metropolis-Hastings sampling)
の概要をご紹介します!
ちなみにシリーズ第1回では、任意の確率分布からのサンプリングが必要になる例をご紹介しました。
シリーズ第3回の今回は、メトロポリスアルゴリズムを用いたMHサンプリングをご紹介します。
MHサンプリングはマルコフ連鎖を利用して目的の分布に従うランダムサンプルを得る方法です。
提案分布から候補点を抽出し、ある確率で採用するという点は棄却サンプリングと共通していますが、マルコフ連鎖(ランダムウォーク)を用いる点が異なります。
この記事ではMHサンプリングの手順に加え、pythonによる簡単な実装例をご紹介します。
複雑な関数形の確率分布からサンプルを得ようとすると、既存のライブラリや逆関数法が使えないことがあります。
このようなときに、棄却サンプリングやMHサンプリングといった非解析的な手法が役に立ちます。
これらの方法であれば、何かしらの方法で確率分布が定式化できれば、その確率分布からランダムサンプルを得ることができます。
しかも、確率分布の規格化が不要(積分が1になる必要がない)なため、大変便利です!
今回は、「任意の確率分布(しかも規格化できていない)からランダムサンプルを得るにはどうしたらいいんだろう?」というみなさんのお悩みを解決します!
ぜひ最後までお付き合いください!
Abstract | 提案分布に悩まないMHサンプリング
前回の記事では、任意の確率分布からランダムサンプルを得る手法として棄却サンプリングを紹介しました。
棄却サンプリングは、手順や解釈が単純で実装しやすいメリットがありました。
一方で、提案分布が目標分布を覆っている必要があるため、目標分布の最大値を知っておく必要があります。
また、変数の領域が\(-\infty, +\infty\)などと制限されていないときには、提案分布として何を設定してよいか悩ましいでしょう。
このような場合は一様分布を使うことができません。
目標分布の最大値が求まらず、変数の領域が制限されていないときには、MHサンプリングが使えます。
MHサンプリングは最初に適当に設定した点(初期値)からランダムウォークを行って目標分布に従うサンプルを創る手法です。
ランダムウォークとは、次に進む点を現在地の周りにランダムに選ぶ手法で、日本語では酔歩と呼ばれます。
MHサンプリングでは、ランダムウォークを与える提案分布(例えば正規分布)から次の候補点をサンプルし、目標分布で与えられる確率に従って、その点を採用します。
提案分布はランダムウォークを与えられさえすればよいので、提案分布の設定が簡単というメリットがあります。
棄却サンプリングのように提案分布が目標分布を覆う必要があると行った条件は課されません。
以下ではMHサンプリングの手順やメリットデメリット、pythonによる実装例をご紹介します!
MHサンプリングをマスターし、どんな分布関数からでもランダムサンプリングできるようになってしまいましょう!
Method | MHサンプリングの手順とメリット・デメリット
このセクションでは、まずMHサンプリングの概要をご紹介し、イメージを掴んでいただきます。
それから具体的な手順を紹介した上で、この手法のメリット・デメリットをお話します。
MHサンプリングの概要
MHサンプリングでは、ランダムウォークを使って目標分布に従うサンプル生成します。
現在のサンプル点\(x_{t}\)の近くにランダムに候補点\(x_{t}^{‘}\)を探します(ランダムウォーク)。
次に、その候補点における目標分布の値と現地点における値の比\(\frac{P(x_{t}^{‘})}{x_{t}}\)に応じて、その候補点に移動するかどうかを決定します。
この比が大きい点に積極的に移動することで、目標分布の値\(P(x)\)の大きい領域で沢山サンプルされ、\(P(x)\)の小さい領域では少なくサンプルされることになります。
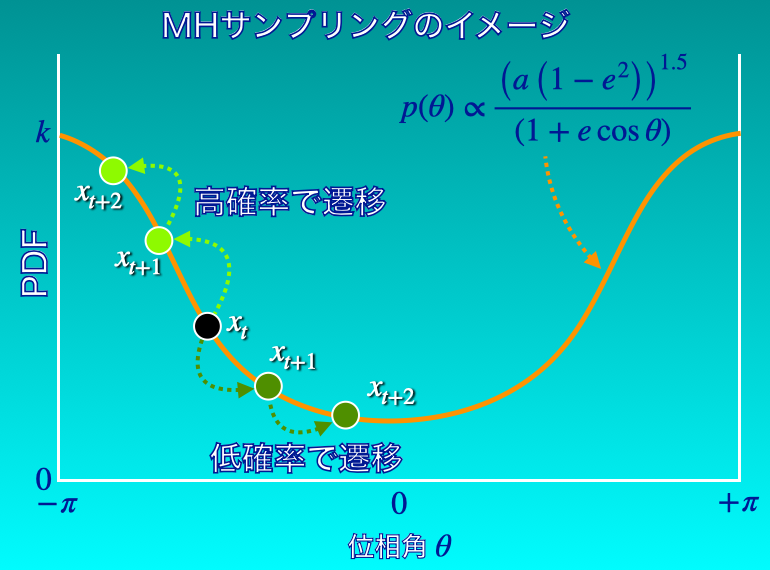
下図1のように、現在地点よりも目標分布の値\(P(x)\)の大きいところにどんどんランダムウォークして移動していくイメージです。
ランダムウォークで候補点を探すので、目標分布の値\(P(x)\)の小さいところも当然サンプルされます。
サンプルされるものの、その割合は小さくなるので、目標分布に従うサンプルを得ることができます。
しっかり解釈しようとすると、棄却サンプリングよりも複雑ですが、直感的にはランダムウォークしながら、\(P(x)\)の大きいところに積極的に移動する(あるいはとどまろうとする)一方で、\(P(x)\)の小さいところもたまにサンプルするイメージです。
MHサンプリングの手順
MHサンプリングでは、以下のような手順でサンプリングを行います。
目標分布を\(P\)とします。
- 初期値\(x_0\)を設定する。
- 提案分布\(Q(x^{\prime} | x)\)を与える。
- 提案分布\(Q(x^{\prime} | x)\)から候補点\(x_{0}^{\prime}\)をサンプルする。
- 採択確率\(\alpha = \frac{P(x_{0}^{\prime})}{P(x_{0})}\)を計算する。
- 採択確率\(\alpha\)によって、次の点\(x_{1}\)を決定する。
\(\alpha \geq 1\)ならば、\(x_{1} = x_{0}^{\prime}\)を採用する。
\(\alpha < 1\)ならば、\(\alpha\)の確率で\(x_{1} = x_{0}^{\prime}\)を採用し、\(1 – \alpha\)の確率で\(x_{1} = x_{0}\)を採用する。 - 3–5の操作を所望のサンプル数が得られるまで繰り返す。
以下で詳しく見ていきます。
提案分布\(Q\)の設定
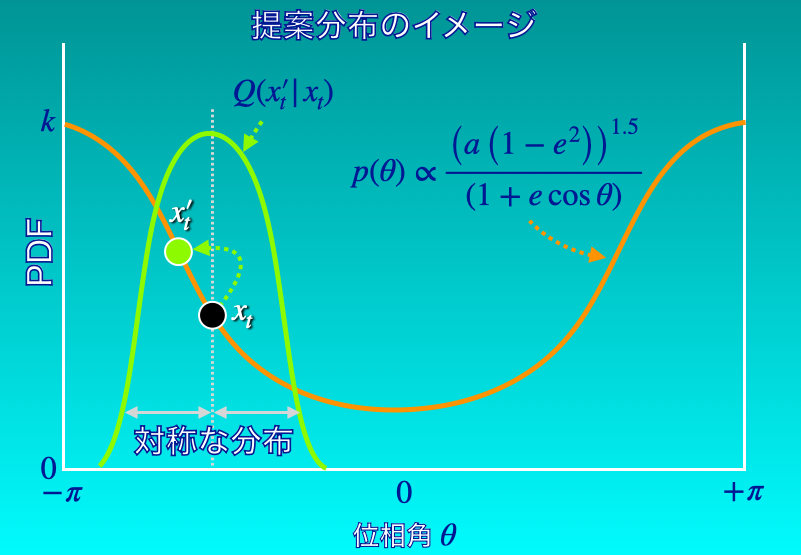
提案分布\(Q(x^{\prime} | x)\)は、現地点\(x\)から次の点\(x^{\prime}\)へのランダムウォークを与える確率分布です。
提案分布は\(x\)について対称な分布である必要があります(下図2)。
例えば、中心が\(x\)で適当な幅を持つ正規分布が該当します。
\(x\)を中心とした対称な分布関数からサンプルすることで、\(x\)を中心としたランダムウォークが実現できます。
提案分布は、ランダムウォークを生成するためだけに存在するため、\(x\)について対称な分布で適当な幅を持ってさえいれば何でも構いません。
「適当な幅」についてはデメリットの方でお話します。
採択確率\(\alpha\)の計算とそれを用いた移動先点\(x_{t+1}\)の採択
採択確率は、目標分布\(P\)だけで計算されます。
ここが棄却サンプリングと異なる点です。
\(x_{1} = x_{0}^{\prime}\)の採択確率は、以下のような式で表されることもありますが、意味合いは上記の手順4–5と同じです。
$$
\alpha = \mathrm{min} \left(1, \frac{ P(x_{0}^{\prime} ) }{ P(x_{0}) } \right)
$$
確率\(\alpha\)で\(x_{1} = x_{0}^{\prime}\)を採択し、\(1-\alpha\)で\(x_{1} = x_{0}\)を採択するところで、
- 現在地よりも目標分布の値が大きければ必ず移動する
- 現在地よりも目標分布の値が小さい場合は、確率\(\alpha\)で移動して、\(1-\alpha\)で現在地にとどまる
というメトロポリスアルゴリズムが働きます。目標分布の値が大きいところをたくさんサンプルし小さいところは少なくサンプルするということが実現されます。
MHサンプリングのメリット
MHサンプリングのメリットは、採択確率の計算を目標分布\(P\)だけで行うため、
- \(P\)の規格化ができない場合や最大値が計算できない場合でも使える
ことです。
目標分布\(P\)の規格化が不要|ベイズ推定と相性が良い
\(P\)の規格化ができない場合の例としてベイズ推定があります。
ベイズ推定においては、たいていは規格化されていない事後分布からのランダムサンプルを得ることを行います。
ベイズの定理は、関心のある事象を\(A\)、実験や観測を\(X\)として
$$
P(A | X) = \frac{P(X | A) P(A)}{P(X)} \propto P(X | A) P(A)
$$
のように表されます。
ベイズ推定において求めたいのは観測\(X\)が得られた条件での\(A\)が起こる条件付き確率\(P(A | X)\)です。
これが目的の事後分布です。すなわち目標分布は\(P(A | X)\)です。
この事後分布を、予め想定しておいた事象\(A\)の事前分布\(P(A)\)と事象\(A\)が与えられた条件で\(X\)が観測される確率\(P(X | A)\)から得るのがベイズ推定です。
通常は\(P(X)\)は求められないので、事後分布は\(P(A | X) \propto P(X | A) P(A)\)という比例の形でしか求められません。
このようなときに、MHサンプリングのようなモンテカルロ・マルコフ連鎖を使って事後分布\(P(A | X)\)をサンプリングで再現します。
目標分布\(P\)の最大値も不要 | 棄却サンプリングに対するメリット1
目標分布\(P\)の最大値が得られないと困るサンプリング方法のひとつに棄却サンプリングがあります。
棄却サンプリングでは、提案分布が目標分布を「覆っている」必要があるため、目標分布の最大値が事前に計算できる必要があります(実装方法によっては不要。第4回をお楽しみに)。
\(P\)の最大値が計算できないこともしばしばあるため、この点はMHサンプリングのメリットです。
提案分布に悩まなくて良い | 棄却サンプリングに対するメリット2
さらに、\(x\)の領域が定まっていない(\((-\infty, +\infty)\))など、棄却サンプリングで提案分布を設定するのが難しい場合にも、MHサンプリングのメリットがあります。
MHサンプリングでは、提案分布は対称なランダムウォークを生成できさえすれば良いので、提案分布の設定が簡単です。
MHサンプリングのデメリット
MHサンプリングのデメリットは
- 得られた乱数列に自己相関があること
- 乱数列の最初の部分は目的分布を再現しないこと
の2つです。
乱数列の自己相関
1つ目の、乱数列の自己相関が乱数列がマルコフ連鎖で得られることに由来します。
MHサンプリングでは、マルコフ連鎖(ランダムウォーク)を使います。
ランダムウォークは、一つ前の状態から次の状態が生成されるので、この2つの状態は必然的に相関します。
時系列の一つ前やそれより前の状態といまの状態が相関することを自己相関と呼びますが、時系列データではしばしば見られる現象です。
乱数列に自己相関があると、後段の分析に悪影響を及ぼすことがあります。
自己相関があると困るごく簡単な例として、2つのデータ系列同士の相関を分析したい場合があります。
自己相関がある独立なデータ系列同士の相関分析を行うと、ほぼ100 %相関が観測されます。
ここでは詳しく取り上げませんが、無関係なランダムウォークを2つ作って相関分析を行うと高い確率で有意な相関が得られます。
乱数列の自己相関を防ぐために、MHサンプリングで得られた乱数列から何個かおきに間隔を空けて値を抽出する、スライシングという作業を行うこともあります。
間隔を十分大きく取れば、時系列的にほとんど関係のなくなった値を抽出することができます。
ただし、その分長い乱数列を得る必要があるため計算時間が長くなります。
Burn-inの必要性
2つめの、乱数列の最初の部分の問題については、最初は初期値のまわりが多くサンプルされることに由来します。
MHサンプリングはランダムウォークを行うので、しばらく時間が経つと最初の状態(初期値)の情報はなくなります。
しかし、それまでの間は初期値に依存するランダムウォークとなります。
言い換えると、最初の方は、目標分布の形にかかわらず初期値のまわりばかりがサンプルされます。
2つめの問題を防ぐために、Burn-inという手法が用いられます。
Burn-inというのは、単純に乱数列の最初の部分を捨てるということです。
どのくらいの乱数列をBurn-inすればよいかというのは、提案分布の幅の広さに依存します。
提案分布の幅はBurn-inと目標分布への収束速度のトレードオフで決める
提案分布の幅は、初期値を忘れるスピードと目標分布の再現のスピードのトレードオフで決定します。
提案分布の幅には、
- 広くするほど初期値を速く忘れる
- けれども広くするほど目標分布の再現性が下がる
というトレードオフがあります。
提案分布の幅を広げれば、現在地から遠くの候補点が提案されやすくなるため、すぐに初期値から離れた点をサンプルすることができます。
そのため、初期値を忘れる速度があがり、Burn-inの長さを短くすることができます。
一方で提案分布の幅を広げると、目標分布の値の大きい地点にいるときに、そのまわりを効率的にサンプルすることができなくなります。
そのため、目標分布の値の大きい領域で自己相関が増える、目標分布の再現性が下がるなどの弊害が生じます。
Result | pythonでの簡単な実装例
MHサンプリングの簡単な実装例をご紹介します。
jupyter notebookでのpython実装例
ソースコードは以下です。
コピー&ペーストして使っていただいて構いませんが、自己責任でご利用ください。
matplotlibはversion3.3.4が必要です(それ以前はhistogramにdensityパラメータがない)。
↓スクロールしてご覧ください。
コーディングのポイント
コーディングのポイントをお話します。
目標分布の設定
目標分布は以下で定義されています。
# 目標の分布
def p(theta, d=100*1000., e=0.1):
return (d * (1-e**2) / (1-e))**1.5 / (1 + e*np.cos(theta))**2theta(\(\theta\))がこの分布関数の変数です。
dとeはoptional argumentsとして渡します。
単に
$$
p(\theta) \propto \frac{\left(d_{P} \left(1 + e\right)\right)^{1.5}}{\left(1 + e \cos \theta \right)}
$$
を返す関数です。
提案分布の設定
提案分布は以下の部分で定義されます。
# proposed distribution: Q(x_{t+1}, x_{t})
def q(t, mu=0.0, sig = 0.25*pi):
z = np.random.normal(mu, sig)
t2 = t + z
# return a value from -pi to pi using atan2
return math.atan2(math.sin(t2), math.cos(t2))提案分布の関数qはmuを中心とsigを標準偏差とする正規分布を現在地tのまわりに生成します。
zは、現在地から次の候補点までの移動を決めるベクトルで、muを中心とsigを標準偏差とする正規分布からランダムにサンプルされる値です。
候補点(\(x_{t}^{\prime}\))の値t2は、zを現在地(\(x_{t}\))の値tに足すことで与えられます。
MHサンプリングでは、提案分布はtに対して対称である必要があります。
したがってmuは0である必要があります。
最後、値を返すところで、\(\theta\)の取りうる値は\([-\pi, +\pi]\)なので、この範囲に収まるように、atan2関数で変換しています。
もしパラメータ\(x\)(この例では\(\theta\))の取りうる値に制限がなければ、この処理は不要です。
# return a value from -pi to pi using atan2
return math.atan2(math.sin(t2), math.cos(t2))メトロポリス法(MCMC; モンテカルロ・マルコフ連鎖)を行う関数
メトロポリス法は以下の関数「MCMC」で実装されています。
# MCMC
def MCMC(p, q, t, arg_p = None, arg_q = None):
# p <function>: target distrubution
# q <function>: proposed distribution
# t <float>: current position
# arg_p <tuple>: arguments passed to f_p
# arg_q <tuple>: arguments passed to f_q
while True:
# proposed sample
t2 = q(t, *arg_q)
# if accepted, return value
if(p(t2, *arg_p) / p(t, *arg_p) > np.random.uniform(0,1)):
return t2
else:
return tこのMCMC関数は、任意の目標分布と提案分布を与えられるようにコードしてあります。
引数pとqは、目標分布と提案分布を与える関数オブジェクトで、MCMCを呼び出すときに、別の箇所で定義されているものを引数として与えます。
tは現在の値、arg_pはpに与える引数(ここではdとe)、arg_qはqに与える引数(ここではmuとsigma)です。
サンプリングを行う関数
サンプリングを行う関数は以下のように定義されています。
# define sampling
def sampling_MH(N, B, p, q, t=0.0, arg_p = None, arg_q = None):
t_samples = np.empty([N])
for i in range(N):
t = MCMC(p, q, t, arg_p=arg_p, arg_q=arg_q)
t_samples[i] = t
return t_samples[B:]このsampling_MH関数で、MCMC関数を呼び出してMHサンプリングを実行します。
引数NはBurn-inを含めた乱数列の長さ、BはBurn-inです。
pとqは目標分布と提案分布を与える関数オブジェクトです。
tはここでは初期値です。
arg_pとarg_qは、MCMC関数でpとqに渡される引数です。
forループを使ってMCMCを進めるので、計算時間がかかります。
実際に私の環境では100万サンプル得るのに14秒程度かかります。
棄却サンプリングで30秒ほどかかっていたことを考えると多少マシになりましたね。
ちなみに、N個の乱数列を作った後、最後”return”で値を返すところで、最初のB個を切り落としています。
サンプリングの実行
MHサンプリング関数(sampling_MH)は以下で呼び出されています。
# get samples using MH algorithm
samples = sampling_MH(N+B, B, p, q, t=t, arg_p = (d, e), arg_q = (mu, sig))Burn-inを含まないNサンプル欲しいので、はじめからN+B個の乱数列をsampling_MH関数のNとして渡しています。
もし目標分布や提案分布をご自分で設定したい場合には、pやqをご自分で定義し、それを必要な引数と一緒に
sampling_MH()に渡せばMHサンプリングが実装できます。
ぜひトライしてみてください!
Conclusion | まとめ
最後までご覧頂きありがとうございました!
メトロポリス・ヘイスティングス(MH)サンプリングの手順とpythonの実装例をご紹介しました!
MHサンプリングは、マルコフ連鎖を使うなど、棄却サンプリングより手順が複雑で、直感的な解釈もやや難しいですが、規格化定数がわからない場合や最大値が求められない場合にも使えるなど便利なサンプリングテクニックです!
提案分布に対する条件も棄却サンプリングより緩いのもメリットのひとつです。
任意の分布からランダムサンプルする必要に迫られたら、MHサンプリングも検討してみてください!
以上「統計学&pythonレシピ | 任意の確率分布からのサンプリング3(MHサンプリング導入編)」でした!
またお会いしましょう!Ciao!
コメント