
みなさんこんにちは!このブログでは主に
の4つのトピックについて発信しています。
今回の記事では時系列データの分析について扱います!
これまでの記事では、時系列データの分析におけるこれまでの記事では、時系列データの分析における「偽物の相関」の危険性↗や、定常性の確認↗・非定常性の性質↗、定常化の代表的な方法↗、そして実データ(株価・GDP・売上)の定常化↗について学んできました。
今回はその次の段階として、定常化した系列をどのようにモデル化するか を見ていきます。具体的には、単変量時系列モデルの代表である ARIMA と SARIMA を取り上げ、どのような系列にどのモデルが向いているのか、Pythonで実際に比較しながら整理します。
👉 この記事を読むことで、
- 定常化の次に、なぜモデル化が必要なのか
- ARIMA と SARIMA をどう使い分ければよいのか
- AIC / BIC、予測誤差、残差診断をどう見ればよいのか
が理解できるはずです。
「時系列データを定常化したあと、次に何をすればよいのだろう?」と感じたことがある方は、ぜひ最後まで読んでみてください。
- Abstract | 系列に合ったモデルを選ぶ
- Introduction | 単変量時系列モデル
- Background | ARIMAとSARIMAの違い
- Data | 月次の小売売上データ
- Method | モデル比較の進め方
- Results | PythonでARIMAとSARIMAを比較する
- Discussion | どのモデルを選ぶべきか
- Conclusion | まとめ
- References | Pythonコードの全文
- 時系列分析シリーズ
Abstract | 系列に合ったモデルを選ぶ
時系列データ分析では、非定常性を見分けて系列を整えることが重要です。ただし、定常化はゴールではありません。整えた系列を予測や構造理解に使うためには、その次にモデル化が必要になります。
本記事では、単変量時系列モデルの代表である ARIMA と SARIMA を取り上げ、月次の小売売上データに対して Python で比較します。具体的には、学習データとテストデータに分割したうえで、両モデルを適用し、
- 予測結果
- AIC / BIC
- 予測誤差
- 残差診断
を比較・評価します。
結果として、今回の月次の小売売上データでは、季節成分を持つ SARIMA のほうが、非季節モデルである ARIMA よりも自然なモデルであることを確認します。一方で、これは常に SARIMA を選べばよいという意味ではなく、系列の性質に応じてモデルを選ぶ必要があることもあわせて示します。
この記事を読めば、定常化した単変量時系列データに対して、ARIMA と SARIMA をどのような観点で比較し、どのように選べばよいかを理解できるようになります。
Introduction | 単変量時系列モデル
第5回までの記事↗では、時系列データにおける非定常性をどのように見分け、どのように扱うかを見てきました。
具体的には、
- 第1回:ランダムウォークが生む偽相関↗
- 第2回:ADF検定による定常性の確認↗
- 第3回:トレンドや季節性がある場合の考え方↗
- 第4回:差分、トレンド除去、季節調整といった定常化手法↗
- 第5回:株価・GDP・売上データに対する定常化手法の適用↗
を順番に整理してきました。
ここまでで、「非定常な系列をそのまま扱うのは危険であり、まず系列の性質を見極めて整える必要がある」という点は押さえられたと思います。
予測や構造理解にはモデル化が必要
第5回までの記事↗で扱ってきた定常化はそれ自体がゴールではありません。
時系列データ分析の目的は
- 将来の値を予測すること
- 系列にどのような構造があるかを理解すること
にあります。したがって、定常化して系列を整えたあとには、
そのデータをモデルで表現する必要があります。
第5回までで扱ってきた定常化は、時系列データをモデル化するための前処理でもあります。
単変量時系列モデルによるモデル化
時系列データをモデル化する方法の1つが、単変量時系列モデルです。
単変量時系列モデルでは、1本の系列だけに注目して、過去の値や過去の誤差、季節的な繰り返しなどを使いながら、系列の動きを表現します。
単変量時系列モデルを使うことで、過去の系列から将来の値を予測できるようになります。
さらに、自己相関や季節性といった系列構造を明示的に捉え、整理して理解しやすくなります。
このように単変量時系列モデルは、予測のための枠組みであると同時に、系列の構造理解のための枠組みでもあります。
ARIMA・SARIMA | 単変量時系列モデルの代表例
単変量時系列モデルにはいくつかの考え方がありますが、その代表が ARIMA と SARIMA です。
ARIMA は、差分を取って定常化した系列に対して、主に非季節の自己相関構造を表現するモデルです。
一方の SARIMA は、ARIMA を拡張して、季節性を含む系列構造を扱えるようにしたモデルです。
したがって、定常化したあとにどのモデルを使うかを考えるとき、まず ARIMA と SARIMA の違いを理解することには大きな意味があります。
特に、季節性があるかどうかは、単変量時系列モデルを選ぶうえで重要な分かれ目になります。
ARIMA・SARIMAによる予測とモデル評価
ARIMA や SARIMA を使うと、定常化した系列に対して予測を行えるようになります。
また、系列の動きをどの程度うまく捉えられているかを、モデルとして評価できるようになります。たとえば、次のような観点です。
- 将来の値をどの程度うまく予測できるか
- AIC や BIC のような情報量規準でどう評価されるか
- 残差に自己相関や季節パターンが残っていないか
こうした評価・比較を通じて、
その系列に対して、どのモデルを使うのが自然か
を判断しやすくなります。
今回の記事では、単変量時系列モデルの代表である ARIMA と SARIMA を取り上げ、どのような系列にどのモデルが向いているのか、どのような観点で比較すればよいのかを整理します。
なお、今回は 単変量モデル に絞って扱います。
複数系列の関係を同時に扱う 多変量モデル については、今回は立ち入りません。こちらは次回以降の話題とします。
Background | ARIMAとSARIMAの違い
この章では、ARIMAとSARIMAの違いを整理します。
ポイントはシンプルです。
ARIMAは非季節の系列向き、SARIMAは季節性のある系列向きです。
大事なのは、モデル名を覚えることではありません。
系列の性質に応じて、どのモデルが自然かを見ることです。
ARIMAが向いている系列
ARIMA は、単変量時系列の基本モデルです。
過去の値や過去の誤差を使って、系列の動きを表現します。
ARIMA という名前は、
- AR: AutoRegressive(自己回帰)
- I: Integrated(差分)
- MA: Moving Average(移動平均)
を意味しています。
ここでいう AR は、過去の値を使って現在の値を説明する部分です。
MA は、過去の誤差の影響を使って現在の値を表現する部分です。
そして I は、差分を取ることで非定常な系列を定常化する部分に対応しています。
第5回まで↗で見てきたように、時系列データはそのままでは非定常なことがあります。
ARIMA は、そうした系列に差分を取り、定常化したうえで自己相関を捉えるモデルです。
特に向いているのは、明確な季節性がない系列です。
たとえば、
- トレンドはあるが、周期的な繰り返しは弱い
- 差分を取ると、自己相関だけを見ればよさそう
- まずは単純なモデルから始めたい
といった場面では、ARIMA が出発点になります。
SARIMAが向いている系列
一方で、時系列には季節性を持つものがあります。
たとえば、月次売上が毎年同じ時期に増減するような系列です。
このようなデータでは、通常の ARIMA だけでは季節パターンを十分に表現できないことがあります。
そこで使うのが SARIMA です。
SARIMA は、Seasonal ARIMA の略です。
つまり、ARIMA に**季節性(Seasonal)**を加えたモデルです。
通常の ARIMA が
- 非季節の AR
- 非季節の差分
- 非季節の MA
を持つのに対して、SARIMA ではこれに加えて、
- 季節差分
- 季節AR項
- 季節MA項
を入れることができます。
そのため、一定周期で繰り返すパターンをモデルの中に組み込めます。
月次データで 12 か月周期の季節性がある場合などは、その構造を明示的に表現できます。
つまり SARIMA は、単に複雑な ARIMA ではありません。
季節性のある系列に対して、より自然な構造を置けるモデルです。
系列の性質に応じてモデルは変わる
ここで重要なのは、
ARIMA と SARIMA の違いは、モデル名の違いではなく、系列構造の違いに対応している
ということです。
- 季節性が弱いなら ARIMA
- 季節性がはっきりしているなら SARIMA
まずはこの理解で十分です。
また、SARIMA のほうが高機能に見えるかもしれません。
しかし、複雑なモデルほどよいとは限りません。
季節性が弱いデータに SARIMA を使っても、改善がほとんどないことがあります。
逆に、季節性が強いのに ARIMA だけで済ませると、残差にパターンが残るかもしれません。
実務で見るべきなのは、
どちらが高級かではなく、どちらの仮定がその系列に合っているかです。
なお、今回は 単変量時系列モデル に絞って話を進めます。
複数の系列の関係を同時に扱う多変量モデルについては、今回は扱わず、次回以降の話題とします。
今回の記事では、この考え方を踏まえて、実際のデータで ARIMA と SARIMA を比較していきます。
Data | 月次の小売売上データ
今回の比較には、月次の小売売上データを使います。
第6回では、単変量時系列モデルの入門比較として、
- 非季節の構造を表現する ARIMA
- 季節性を明示的に扱う SARIMA
を比べます。
そのためには、単変量で、季節性が見えやすい系列が適しています。
月次の小売売上データは、その条件を満たしやすい題材です。
月次の小売売上データは非定常で季節性が含まれる
月次の小売売上には、長期的なトレンドと季節的な変動が含まれることがあります。
景気や消費動向の変化は、売上水準の上昇や低下として現れます。
また、年末商戦や季節イベントの影響は、毎年似た時期の売上変動として現れます。
長期トレンドがあれば、売上系列はそのままでは非定常かもしれません。
毎年ほぼ同じ時期に似た動きがあれば、売上系列には季節性が含まれていると考えられます。
このように、月次の小売売上データは、ARIMA と SARIMA の違いを確認しやすい系列です。
ARIMA/SARIMAを適用するときのチェックポイント
ARIMA や SARIMA を当てる前には、売上系列の性質を確認する必要があります。
特に見たいポイントは、次の3つです。
- トレンドがあるか
- 季節性があるか
- 学習用と評価用に分けられるだけの長さがあるか
トレンドが強ければ、非定常である可能性があります。
季節性がはっきりしていれば、SARIMA を候補に入れる理由が強くなります。
観測期間が短すぎると、モデル比較は安定しにくくなります。
モデルを選ぶ前にデータの性質を確認する
ここで押さえたいのは、
モデル選択はデータ理解のあとに来る
ということです。
月次の小売売上データは、ARIMA と SARIMA の違いを見やすい系列です。
ただし、月次売上データだからといって、いつでも SARIMA を選べばよいわけではありません。
まず確認すべきなのは、
- 売上水準にトレンドがあるか
- 年ごとの繰り返しが見えるか
- 比較に使えるだけの観測期間があるか
という点です。
そのうえで、ARIMA で十分なのか、SARIMA で季節性を明示的に扱うべきなのかを判断します。
次の章では、月次の小売売上データを学習用データとテスト用データに分け、ARIMA と SARIMA をどのように比較するかを見ていきます。
Method | モデル比較の進め方
この章では、月次の小売売上データに対して、ARIMA と SARIMA をどのように比較するかを整理します。同じデータに対して ARIMA と SARIMA を適用し、予測結果とモデルの妥当性を比較・評価します。
予測結果を評価するには、学習用データとは別にテスト用データが必要です。そのため、今回は次の流れで分析を進めます。
- データを学習用とテスト用に分割する
- ARIMA と SARIMA を適用する
- 予測結果やモデルの妥当性を評価する
比較・評価の観点は、主に次の3つです。
- AIC / BIC
- テストデータに対する予測誤差
- 残差にパターンが残っていないか
つまり今回は、同じデータに 2 つのモデルを当てて、複数の観点から比較します。
学習データ・テストデータの分割 | 時系列の順序を保つ
ARIMA と SARIMA を比較するために、データを学習データとテストデータに分割します。
ここで重要なのは、時系列データでは時間の順序を崩してはいけないということです。通常の機械学習では、データをランダムにシャッフルして学習用と評価用に分けることがありますが、時系列データではその方法は適しません。
なぜなら、時系列分析では「過去から未来を予測する」ことが目的だからです。未来のデータを学習に混ぜると、本来は使えない情報を使って予測することになり、評価が不自然に良く見えてしまいます。
そのため今回は、前半を学習データ、後半をテストデータとして分けます。このように時間順を保った分割にすることで、実際の予測に近い形でモデルを比較できます。
ARIMA と SARIMA の適用
次に、同じ売上系列に対して ARIMA と SARIMA を当てはめます。
ここで大切なのは、比較条件をそろえることです。どちらのモデルも同じ学習データで推定し、同じテストデータで予測性能を確認します。
今回の比較では、ARIMA を非季節モデルの基準として扱います。一方の SARIMA では、ARIMA の枠組みに季節成分を加えます。
つまり比較したいのは、
- 季節性を明示的に入れない ARIMA
- 季節性を明示的に入れる SARIMA
の違いです。
月次の小売売上データでは、年ごとの繰り返しが強ければ SARIMA のほうが自然なモデルになる可能性があります。逆に、季節性が弱ければ ARIMA でも十分かもしれません。
このように、同じ系列に 2 つのモデルを当てることで、季節性を明示的に扱うことにどれだけ意味があるかを確認できます。
予測結果・妥当性の評価 | 複数指標を使う
モデル比較では、1つの指標だけで結論を出さないことが重要です。
まずよく使われるのが、AIC や BIC のような情報量規準です。これらは、モデルの当てはまりの良さだけでなく、複雑さも考慮して評価する指標です。一般には、値が小さいほど望ましいと解釈されます。
ただし、AIC や BIC が良いからといって、それだけで十分とは言えません。実際に知りたいのは、未知のデータに対してどの程度うまく予測できるかだからです。
そこで、テストデータに対する予測値を作り、MAE や RMSE などの予測誤差を比べます。これによって、学習データへの当てはまりではなく、将来データに対する性能を確認できます。
さらに重要なのが残差診断です。残差に自己相関や季節パターンが残っていれば、モデルが系列構造を十分に捉えられていない可能性があります。
つまり今回の比較では、
- AIC / BIC でモデルの複雑さを含めて見る
- 予測誤差で将来データへの性能を見る
- 残差診断で系列構造を取り切れているかを見る
という 3 つの観点をあわせて確認します。
モデル比較は1つの数字だけでは決められない
ここで押さえたいのは、モデル比較は1つの指標だけでは決められないということです。
たとえば、AIC は良くても予測誤差が大きいかもしれません。予測誤差は小さくても、残差に明らかな季節パターンが残っているかもしれません。
そのため、モデル比較では
- 学習データへの当てはまり
- テストデータでの予測性能
- 残差の妥当性
をまとめて見る必要があります。
次の章では、実際に ARIMA と SARIMA を当てはめて、予測結果・情報量規準・残差の違いを確認します。
Results | PythonでARIMAとSARIMAを比較する
この章では、月次の小売売上データに対して ARIMA と SARIMA を実際に適用し、Python で比較します。
比較の流れはシンプルです。
まずデータを取得して学習用・テスト用に分割し、その後 ARIMA と SARIMA を推定します。最後に、予測結果、AIC / BIC、予測誤差、残差診断を並べて確認します。
必要なライブラリと補助関数を準備する
まず、今回の比較に必要なライブラリと補助関数を用意します。
この段階で、データ取得、学習・テスト分割、モデル探索、予測誤差計算、Ljung-Box 検定まで一通り使えるようにしておきます。
ライブラリインポート
必要なライブラリをインポートしておきます。ここでついでにwarningsの設定を"ignore"にしておきます。
import warnings
from itertools import product
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import display
from sklearn.metrics import mean_absolute_error, mean_squared_error
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.stats.diagnostic import acorr_ljungbox
warnings.filterwarnings("ignore")関数準備
下記の関数を用意しておきます:
- `download_fred_series`: データ取得
- `train_test_split_ts`: 学習・テスト分割
- `fit_sarimax_model`: SARIMAモデルのフィット
- `search_best_arima`: ARIMAモデルの探索
- `search_best_sarima`: SARIMAモデルの探索
- `forecast_with_ci`: 将来予測実施
- `calc_forecast_metrics`: 予測誤差計算
- `ljung_box_table`: Ljung-Box 検定
def download_fred_series(series_id: str, start: str = None, end: str = None) -> pd.Series:
"""Download a FRED series as a pandas Series."""
url = f"https://fred.stlouisfed.org/graph/fredgraph.csv?id={series_id}"
df = pd.read_csv(url)
df.columns = ["date", "value"]
df["date"] = pd.to_datetime(df["date"])
df["value"] = pd.to_numeric(df["value"], errors="coerce")
df = df.dropna().sort_values("date")
if start is not None:
df = df[df["date"] >= pd.to_datetime(start)]
if end is not None:
df = df[df["date"] <= pd.to_datetime(end)]
series = pd.Series(df["value"].values, index=df["date"], name=series_id)
series.index = pd.DatetimeIndex(series.index, freq="MS")
return series
def train_test_split_ts(series: pd.Series, test_size: int):
"""Split a time series into train and test sets while preserving time order."""
train = series.iloc[:-test_size].copy()
test = series.iloc[-test_size:].copy()
return train, test
def fit_sarimax_model(
series: pd.Series,
order: tuple,
seasonal_order: tuple,
trend: str = "n",
):
"""Fit a SARIMAX model."""
model = SARIMAX(
series,
order=order,
seasonal_order=seasonal_order,
trend=trend,
enforce_stationarity=False,
enforce_invertibility=False,
)
result = model.fit(disp=False)
return result
def search_best_arima(series: pd.Series, p_values, d_values, q_values, trend: str = "n"):
"""Search ARIMA orders by AIC."""
records = []
for order in product(p_values, d_values, q_values):
try:
result = fit_sarimax_model(
series=series,
order=order,
seasonal_order=(0, 0, 0, 0),
trend=trend,
)
records.append(
{
"model": "ARIMA",
"order": order,
"seasonal_order": (0, 0, 0, 0),
"aic": result.aic,
"bic": result.bic,
"result": result,
}
)
except Exception:
continue
results_df = pd.DataFrame(records).sort_values("aic").reset_index(drop=True)
best_row = results_df.iloc[0]
return best_row, results_df
def search_best_sarima(
series: pd.Series,
p_values,
d_values,
q_values,
sp_values,
sd_values,
sq_values,
seasonal_period: int,
trend: str = "n",
):
"""Search SARIMA orders by AIC."""
records = []
for order in product(p_values, d_values, q_values):
for seasonal_params in product(sp_values, sd_values, sq_values):
seasonal_order = (
seasonal_params[0],
seasonal_params[1],
seasonal_params[2],
seasonal_period,
)
if seasonal_order[:3] == (0, 0, 0):
continue
try:
result = fit_sarimax_model(
series=series,
order=order,
seasonal_order=seasonal_order,
trend=trend,
)
records.append(
{
"model": "SARIMA",
"order": order,
"seasonal_order": seasonal_order,
"aic": result.aic,
"bic": result.bic,
"result": result,
}
)
except Exception:
continue
results_df = pd.DataFrame(records).sort_values("aic").reset_index(drop=True)
best_row = results_df.iloc[0]
return best_row, results_df
def forecast_with_ci(result, steps: int):
"""Forecast future values and return mean forecast and confidence intervals."""
forecast_res = result.get_forecast(steps=steps)
pred_mean = forecast_res.predicted_mean
conf_int = forecast_res.conf_int()
return pred_mean, conf_int
def calc_forecast_metrics(y_true: pd.Series, y_pred: pd.Series) -> dict:
"""Calculate forecast error metrics."""
mae = mean_absolute_error(y_true, y_pred)
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
mape = np.mean(np.abs((y_true - y_pred) / y_true)) * 100
return {"MAE": mae, "RMSE": rmse, "MAPE_pct": mape}
def ljung_box_table(residuals: pd.Series, lags=(12, 24)) -> pd.DataFrame:
"""Run Ljung-Box test for selected lags."""
lb = acorr_ljungbox(residuals, lags=list(lags), return_df=True)
lb = lb.rename(columns={"lb_stat": "LB_stat", "lb_pvalue": "LB_pvalue"})
return lb月次の小売売上データを取得して確認する
次に、FRED から月次の小売売上データを取得します。
今回は RSXFSN を使います。月次データなので、SARIMA の季節周期は 12 とします。
データ取得・分析用のパラメータ設定
下記のパラメータを設定しておきます。
- データ取得のパラメータ
- テストデータ期間
- 季節性の周期
- ARIMAのハイパーパラメータ(モデルの次数の探索範囲)
- SARIMAのハイパーパラメータ(モデルの次数の探索範囲)
# params for data download
SERIES_ID = "RSXFSN"
START_DATE = "2000-01-01"
END_DATE = None
# params for test-data size and seasonality
TEST_SIZE = 24
SEASONAL_PERIOD = 12
# hyper params for ARIMA
P_VALUES = [0, 1, 2]
D_VALUES = [1]
Q_VALUES = [0, 1, 2]
# hyper params for SARIMA
SP_VALUES = [0, 1]
SD_VALUES = [0, 1]
SQ_VALUES = [0, 1]データ取得とプロット
実際にデータを取得し、プロットして確認します。
# data download
y = download_fred_series(SERIES_ID, START_DATE, END_DATE)
print("Data range:", y.index.min().date(), "to", y.index.max().date())
print("Number of observations:", len(y))
display(y.tail())
# plot
plt.figure(figsize=(12, 4))
plt.plot(y.index, y.values)
plt.title("Monthly Retail Sales (RSXFSN)")
plt.xlabel("Date")
plt.ylabel("Sales")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()ここまで実行すると、
Data range: 2000-01-01 to 2026-02-01
Number of observations: 314
date
2025-10-01 642315
2025-11-01 640201
2025-12-01 716924
2026-01-01 582149
2026-02-01 562351
Freq: MS, Name: RSXFSN, dtype: int64上記のように出力され、下図1が表示されます。
ダウンロードデータの確認
下図1では、売上系列の長期的な変化と、月次の繰り返しがありそうかどうかをざっと確認します。
ここでは厳密な判定よりも、ARIMA と SARIMA を比べる題材として自然かどうかを見ることが目的です。
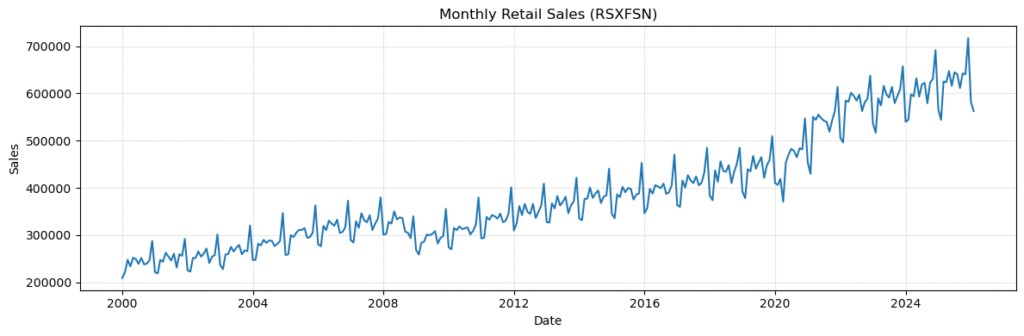
グラフを見ると、売上水準は長期的に上昇しており、月ごとの変動も比較的大きいことがわかります。
また、年ごとに似た時期に山や谷が現れているようにも見えます。
この時点では厳密な判定をする必要はありませんが、少なくともこの系列は、
– トレンドを含んでいそうである
– 季節的な繰り返しを含んでいそうである
という点で、ARIMA と SARIMA を比較する題材として自然だと言えます。
学習データとテストデータに分割する
次に、月次の小売売上データを学習用とテスト用に分けます。
ここでは、最後の 24 か月をテストデータとして使います。
# split data into train and test
train, test = train_test_split_ts(y, TEST_SIZE)
# check splitted data
print("Train period:", train.index.min().date(), "to", train.index.max().date())
print("Test period :", test.index.min().date(), "to", test.index.max().date())
print("Train length:", len(train), "| Test length:", len(test))
# plot
plt.figure(figsize=(12, 4))
plt.plot(train.index, train.values, label="Train")
plt.plot(test.index, test.values, label="Test")
plt.axvline(test.index[0], linestyle="--", color="gray")
plt.title("Train / Test Split")
plt.xlabel("Date")
plt.ylabel("Sales")
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
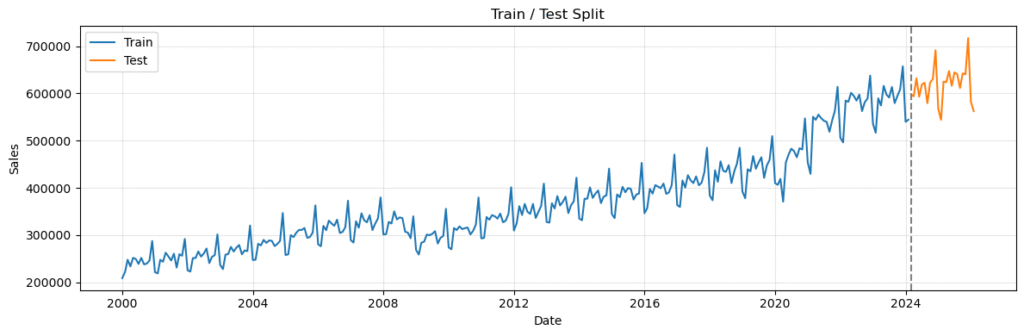
plt.show()実行すると下記のように出力され、下図2が表示されます。
Train period: 2000-01-01 to 2024-02-01
Test period : 2024-03-01 to 2026-02-01
Train length: 290 | Test length: 24今回は、最後の 24 か月をテストデータ、それ以前を学習データとしました。
実行結果では、
- 学習期間:2000-01-01 〜 2024-02-01
- テスト期間:2024-03-01 〜 2026-02-01
- 学習データ数:290
- テストデータ数:24
となりました。
学習・テストデータ分割の確認
この分割により、過去データでモデルを推定し、将来に相当する区間で予測性能を確認できます。
時系列分析では、ランダムにシャッフルせず、時間順を保ったまま分割することが重要です。
下図2でその様子が確認できます。
ARIMA と SARIMA を推定する
次に、学習データに対して ARIMA と SARIMA を推定します。
今回は、次数をいくつか試し、その中で AIC が最小のモデルを採用します。
# find best ARIMA
best_arima, arima_candidates = search_best_arima(
series=train,
p_values=P_VALUES,
d_values=D_VALUES,
q_values=Q_VALUES,
trend="n",
)
# find best SARIMA
best_sarima, sarima_candidates = search_best_sarima(
series=train,
p_values=P_VALUES,
d_values=D_VALUES,
q_values=Q_VALUES,
sp_values=SP_VALUES,
sd_values=SD_VALUES,
sq_values=SQ_VALUES,
seasonal_period=SEASONAL_PERIOD,
trend="n",
)
# check result
print("Best ARIMA order:", best_arima["order"])
print("Best ARIMA AIC :", round(best_arima["aic"], 2))
print("Best SARIMA order:", best_sarima["order"])
print("Best SARIMA seasonal order:", best_sarima["seasonal_order"])
print("Best SARIMA AIC :", round(best_sarima["aic"], 2))
display(arima_candidates.head(10)[["order", "seasonal_order", "aic", "bic"]])
display(sarima_candidates.head(10)[["order", "seasonal_order", "aic", "bic"]])
arima_result = best_arima["result"]
sarima_result = best_sarima["result"]ARIMA・SARIMAモデルの次数
ここでいう次数とは、モデルにどのような構造を持たせるかを表すパラメータです。
ARIMA の次数(p, d, q)は、
– p:自己回帰(AR)の次数
– d:差分の次数
– q:移動平均(MA)の次数
を表します。
SARIMA では、これに加えて季節成分の次数(P, D, Q, s)を指定します。
– P:季節自己回帰の次数
– D:季節差分の次数
– Q:季節移動平均の次数
– s:季節周期
です。今回のデータは月次データなので、季節周期はs = 12としています。
今回は、いくつかの次数の候補を試し、その中からAIC が最も小さいモデルを採用します。
ARIMA・SARIMAモデル探索の結果
上記のコードを実行すると下記のように表示されます。
Best ARIMA order: (2, 1, 2)
Best ARIMA AIC : 6695.5
Best SARIMA order: (1, 1, 2)
Best SARIMA seasonal order: (0, 1, 1, 12)
Best SARIMA AIC : 5664.51また、今回のARIMA・SARIMAの探索結果の一覧も下図3のように表示されます。
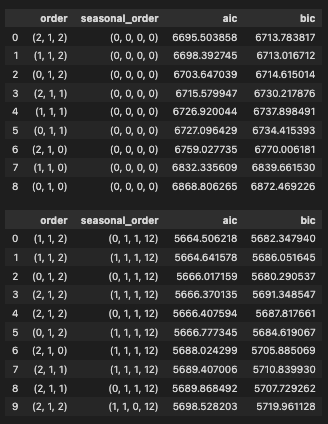
今回は、いくつかの次数の候補を試し、その中からAIC が最も小さいモデルを採用しました。
実行結果では、次のモデルが選ばれました。
– ARIMA(2,1,2)
– SARIMA(1,1,2)(0,1,1,12)
AIC は、
– ARIMA: 6695.50
– SARIMA: 5664.51
でした。
AIC の差は1030.99であり、今回試した候補の中では SARIMA のほうが当てはまりと複雑さのバランスがよいことがわかります。1割を超えるような大きな差が大きいため、月次の小売売上データには季節成分を入れたほうが自然である可能性が高いと考えられます。
予測結果を可視化する
推定した ARIMA と SARIMA を使って、テスト期間の売上を予測します。
まずはグラフで実測値と予測値を重ねて見ます。
# get forcast by ARIMA/SARIMA
arima_forecast, arima_ci = forecast_with_ci(arima_result, len(test))
sarima_forecast, sarima_ci = forecast_with_ci(sarima_result, len(test))
# plot forecast on whole period
plt.figure(figsize=(12, 5))
plt.plot(train.index, train.values, label="Train")
plt.plot(test.index, test.values, label="Test")
plt.plot(test.index, arima_forecast.values, label="ARIMA Forecast")
plt.plot(test.index, sarima_forecast.values, label="SARIMA Forecast")
plt.axvline(test.index[0], linestyle="--", color="gray")
plt.title("ARIMA vs SARIMA Forecast")
plt.xlabel("Date")
plt.ylabel("Sales")
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# plot forecast on test period
plt.figure(figsize=(12, 5))
plt.plot(test.index, test.values, label="Test")
plt.plot(test.index, arima_forecast.values, label="ARIMA Forecast")
plt.fill_between(
test.index,
arima_ci.iloc[:, 0].values,
arima_ci.iloc[:, 1].values,
alpha=0.2,
)
plt.plot(test.index, sarima_forecast.values, label="SARIMA Forecast")
plt.fill_between(
test.index,
sarima_ci.iloc[:, 0].values,
sarima_ci.iloc[:, 1].values,
alpha=0.2,
)
plt.title("Forecast Comparison on Test Period")
plt.xlabel("Date")
plt.ylabel("Sales")
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()ARIMA・SARIMAによる予測結果
上記のコードを実行すると下図4と5が表示されます。ここでは、ARIMA と SARIMA の予測が
- 水準をどの程度追えているか
- 山や谷のタイミングをどの程度再現しているか
- 季節変動をどの程度捉えているか
を確認します。
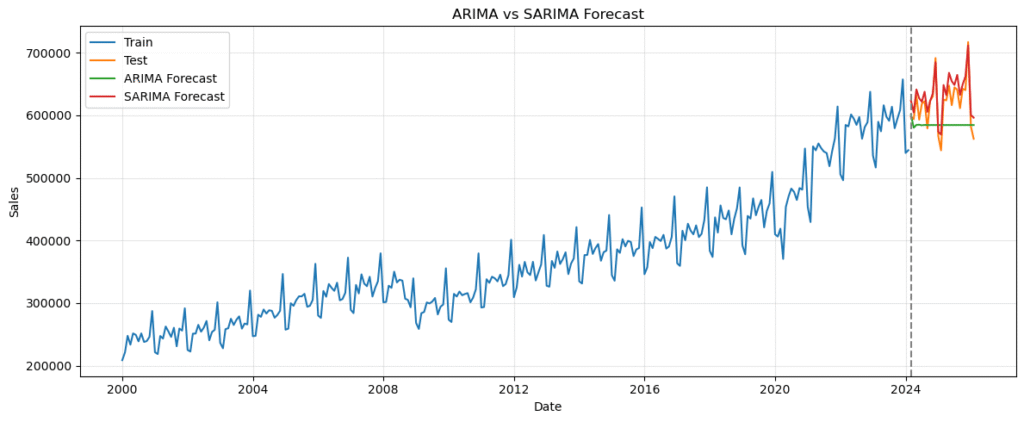
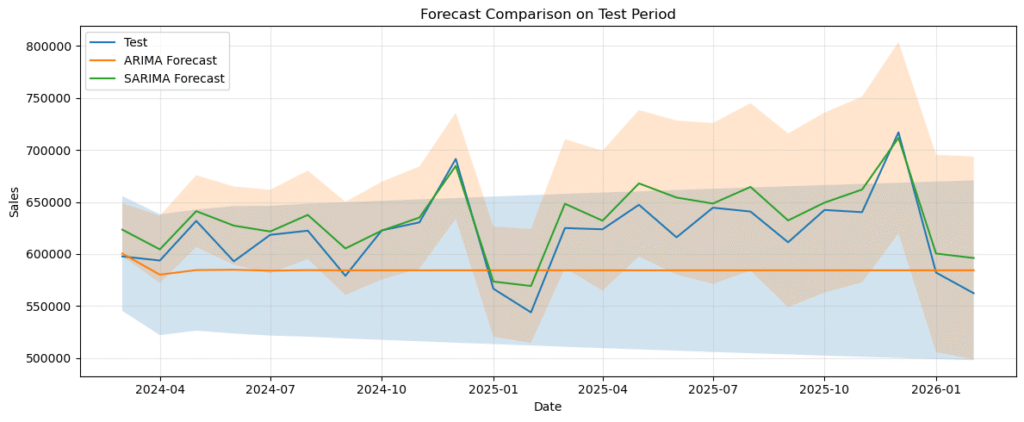
グラフを見ると、ARIMA と SARIMA の違いははっきりしています。
ARIMA の予測はほぼ横ばいに近く、テスト期間の細かな上下動を十分に追えていません。一方で SARIMA の予測は、月ごとの変動にあわせて上下しており、実測値の動きにかなり近い形になっています。
特に、2024 年春から 2025 年末にかけての上下動や、2025 年末付近の高い売上水準に対して、SARIMA のほうが自然に追随しています。
ARIMA は全体の平均水準付近にとどまりやすく、季節的な振れを十分に表現できていません。
この結果から、季節性を明示的に入れることが予測に効いていることがわかります。
予測結果・妥当性の評価 | 複数指標を使う
次に、AIC / BIC と予測誤差を比較します。
数値として比較すると、グラフだけでは見えにくい違いを整理しやすくなります。
# get metrics
arima_metrics = calc_forecast_metrics(test, arima_forecast)
sarima_metrics = calc_forecast_metrics(test, sarima_forecast)
# genereate dataframe
comparison_df = pd.DataFrame(
[
{
"Model": "ARIMA",
"Order": best_arima["order"],
"Seasonal_Order": best_arima["seasonal_order"],
"AIC": arima_result.aic,
"BIC": arima_result.bic,
**arima_metrics,
},
{
"Model": "SARIMA",
"Order": best_sarima["order"],
"Seasonal_Order": best_sarima["seasonal_order"],
"AIC": sarima_result.aic,
"BIC": sarima_result.bic,
**sarima_metrics,
},
]
)
# sort and display metrics
comparison_df = comparison_df.sort_values("RMSE").reset_index(drop=True)
display(comparison_df)予測結果・妥当性の評価結果
上記のコードを実行すると下図6が表示されます。

ここでは、
- AIC / BIC で当てはまりと複雑さのバランスを見る
- MAE / RMSE / MAPE でテスト期間の予測性能を見る
という 2 つの観点を並べます。
どちらか 1 つだけで決めるのではなく、複数の指標をあわせて読みます。
実行結果は次の通りでした。
– SARIMA
– AIC: 5664.51
– BIC: 5682.35
– MAE: 16401.22
– RMSE: 19643.69
– MAPE: 2.71%
– ARIMA
– AIC: 6695.50
– BIC: 6713.78
– MAE: 41141.26
– RMSE: 50962.86
– MAPE: 6.43%
今回の比較では、AIC / BIC と予測誤差のすべてで SARIMA が ARIMA を上回る結果になりました。
AIC の差は 1030.99、BIC の差は 1031.43 となっており、どちらも1割を超えるような大きな差があります。
予測誤差を比べると、
– MAE は 41141.26 → 16401.22 で、SARIMA は ARIMA の約 40%
– RMSE は 50962.86 → 19643.69 で、SARIMA は ARIMA の約 38%
– MAPE は 6.43% → 2.71% で、SARIMA は ARIMA の約 42%
となりました。
言い換えると、SARIMA の予測誤差は、
– MAE で 約 60% 減
– RMSE で 約 62% 減
– MAPE で 約 58% 減
となっており、ARIMAと比べるでSARIMAの誤差はの半分以下となっています。
つまり今回のデータでは、SARIMA は学習データへの当てはまりだけでなく、テスト期間に対する予測性能でも ARIMA より優れていました。
残差診断でモデルの妥当性を確認する
最後に、残差を確認します。
予測誤差が小さくても、残差に自己相関や季節パターンが残っていれば、系列構造を十分に捉えられていない可能性があります。
# get residual
arima_resid = arima_result.resid.dropna()
sarima_resid = sarima_result.resid.dropna()
# plot acf
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
axes[0, 0].plot(arima_resid.index, arima_resid.values)
axes[0, 0].set_title("ARIMA Residuals")
axes[0, 0].grid(True, alpha=0.3)
axes[0, 1].plot(sarima_resid.index, sarima_resid.values)
axes[0, 1].set_title("SARIMA Residuals")
axes[0, 1].grid(True, alpha=0.3)
plot_acf(arima_resid, lags=24, ax=axes[1, 0])
axes[1, 0].set_title("ARIMA Residual ACF")
plot_acf(sarima_resid, lags=24, ax=axes[1, 1])
axes[1, 1].set_title("SARIMA Residual ACF")
plt.tight_layout()
plt.show()
# Ljung-Box test
print("ARIMA Ljung-Box")
display(ljung_box_table(arima_resid, lags=(12, 24)))
print("SARIMA Ljung-Box")
display(ljung_box_table(sarima_resid, lags=(12, 24)))残差診断の結果
上記のコードを実行して、残差診断の結果を見ていきます。
残差の自己相関
上記のコードを実行すると、下図7が表示されます。
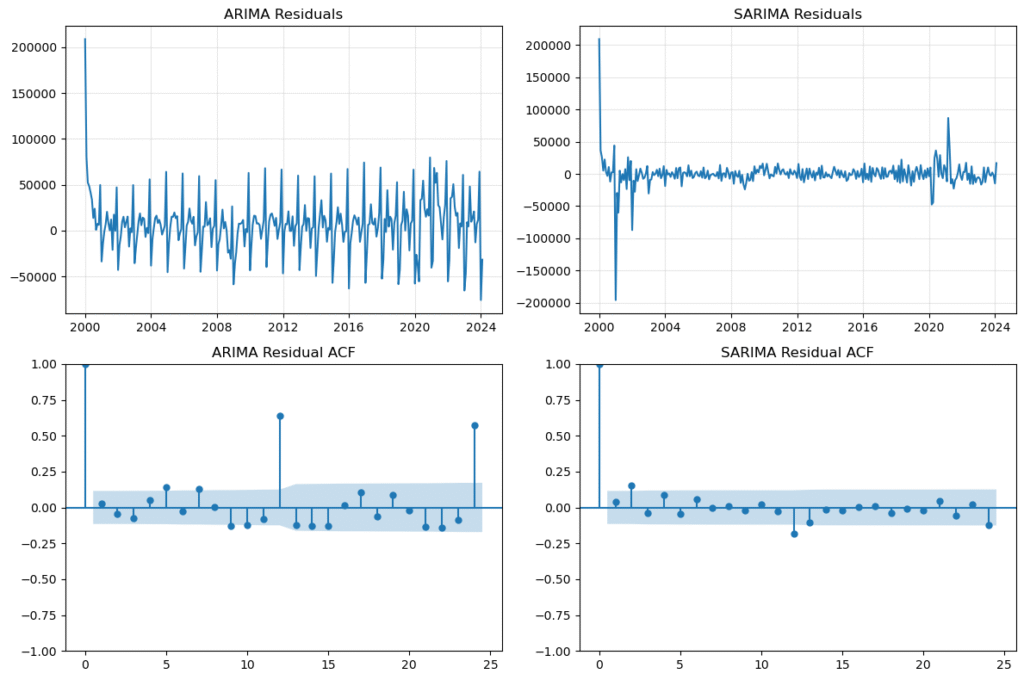
ARIMA の残差系列を見ると、周期的な振れが残っており、残差 ACF でも 12 か月ラグと 24 か月ラグで大きな自己相関が見られます。
一方で SARIMA の残差は、ARIMA と比べて自己相関が小さくなっています。
残差 ACF でも、12 か月ラグと 24 か月ラグの相関は ARIMA より低くなっています。
Ljung-Box検定
Ljung-Box検定は、指定したラグまでの自己相関がまとめて 0 であるかどうかを検定するものです。
帰無仮説は、残差に自己相関がなく、ホワイトノイズとみなせるというものです。
したがって、p値が小さい場合は、残差に自己相関が残っていると判断しやすくなります。
さきほどのコードを実行すると、下記のようにLjung-Box検定の結果が表示されます。
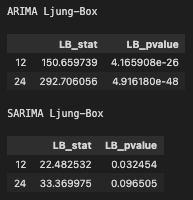
ARIMAのLjung-Box 検定の結果は、
– lag 12: p値 = 4.17e-26
– lag 24: p値 = 4.92e-48
となっており、帰無仮説は棄却されます。
したがって、ARIMA の残差には自己相関が残っており、ホワイトノイズとはみなせないと考えられます。
SARIMAのLjung-Box 検定の結果は
– lag 12: p値 = 0.032
– lag 24: p値 = 0.097
でした。
この結果は、SARIMA が売上系列の季節構造を取り込めていることを示しています。
ただし、lag 12 では p値が 0.05 未満なので、12 か月までの自己相関はまだ残っていると解釈できます。
一方、lag 24 では p値が 0.05 を上回るため、24 か月までをまとめて見た場合には、帰無仮説を棄却しません。
つまり、今回の比較では
- ARIMA では季節パターンが残差に強く残る
- SARIMA ではその残り方が小さくなる
- ただし、SARIMAでも12か月ラグ周辺の自己相関は完全には消えていない
という違いが確認できました。
このように、残差系列、残差 ACF、Ljung-Box 検定をあわせて見ることで、モデルが系列構造をどこまで取り切れているか を確認できます。
結果をまとめて確認する
最後に、採用された次数と比較表をまとめて確認します。
print("Best ARIMA order:", best_arima["order"])
print("Best SARIMA order:", best_sarima["order"])
print("Best SARIMA seasonal order:", best_sarima["seasonal_order"])
print()
display(comparison_df)結果のまとめ
上記のコードを実行すると、下図8が出力されます。
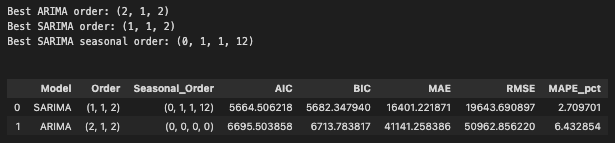
ここまでの結果をまとめると、今回選ばれたモデルは
– ARIMA(2,1,2)
– SARIMA(1,1,2)(0,1,1,12)
でした。
そして比較結果を見ると、
– 予測グラフでは SARIMA のほうが実測値の上下動をよく追えていた
– AIC / BIC では SARIMA のほうが小さかった
– MAE / RMSE / MAPE でも SARIMA のほうが良かった
– 残差診断でも SARIMA のほうが季節構造をより取り切れていた
という結果になりました。
したがって、今回の月次の小売売上データでは、非季節モデルである ARIMA よりも、季節成分を持つ SARIMA のほうが自然なモデルだったと言えます。
ただし、最終判断は 1 つの数字だけで行うものではありません。
今回 SARIMA が有利だったのは、AIC / BIC、予測誤差、残差診断の複数の観点で一貫して良い結果を示したからです。
次の Discussion では、この結果を踏まえて、どのような系列にどのモデルを選ぶのが自然かを整理します。
Discussion | どのモデルを選ぶべきか
ここまで、月次の小売売上データに対して ARIMA と SARIMA を適用し、予測結果、情報量規準(AIC/BIC)、予測誤差、残差診断を比較してきました。
この章では、その結果を踏まえて、どのような系列にどのモデルを選ぶのが自然かを整理します。
今回の結果だけを見れば、月次の小売売上データには SARIMA のほうが適していました。
ただし、これは「常に SARIMA を選べばよい」という意味ではありません。重要なのは、系列の性質に応じてモデルを選ぶことです。
そこで以下では、季節性がある系列ではなぜ SARIMA が有力になるのか、逆にどのような場合には ARIMA で十分なのか、そして実務では精度以外に何を比較軸として持つべきかを順番に整理します。
季節性があるならSARIMAが有力になる
今回の月次の小売売上データでは、SARIMA のほうが自然なモデルでした。
予測結果、AIC / BIC、予測誤差、残差診断のいずれを見ても、季節成分を持つ SARIMA のほうがデータの構造に合っていました。
この結果は、月次データに年ごとの繰り返しが含まれている場合には、SARIMA が有力になりやすいことを示しています。
SARIMA は、ARIMA に季節成分を加えたモデルです。そのため、12か月周期のような繰り返しをモデルの中に明示的に持つことができます。
今回のように、売上系列に年ごとの上下動が見られる場合、非季節モデルである ARIMA だけでは、その構造を十分に表現できないことがあります。
一方、SARIMA では季節差分や季節 AR / MA 項を通じて、周期構造を扱うことができます。
したがって、季節性がはっきりしている系列では、まず SARIMA を候補に入れるのが自然です。
ARIMAで十分な場合もある
ただし、SARIMA を使えばいつでもよいわけではありません。
系列によっては、ARIMA で十分な場合もあります。
たとえば、
- 季節性が弱い場合
- データ期間が短い場合
- 季節成分を入れても改善が小さい場合
です。
SARIMA は、ARIMA よりも多くの構造を扱える一方で、モデルは複雑になります。
そのため、季節性が明確でないデータに対して SARIMA を使っても、複雑さに見合う改善が得られないことがあります。
また、データ期間が短い場合には、季節周期を安定して学習しにくくなります。
月次データで 12 か月周期を考えるなら、少なくとも複数年分の観測がないと、季節構造を十分に見極めにくくなります。
このような場合には、無理に SARIMA を使うよりも、まずは ARIMA のようなより単純なモデルから始めるほうが適切です。
特に実務では、改善幅が小さいなら、シンプルで説明しやすいモデルを選ぶ価値もあります。
モデル比較は精度だけでは終わらない
今回の比較では、SARIMA のほうが予測性能でも優れていました。
ただし、モデル選択は予測精度だけで決めればよいわけではありません。
実務で重要なのは、少なくとも次の3点です。
- モデルの前提が、その系列に対して自然か
- 結果を説明しやすいか
- 継続的に使い続けやすいか
まず重要なのは、前提の妥当性です。
今回で言えば、月次の売上系列に季節性があるなら、季節成分を持つ SARIMA の前提は自然です。
逆に、季節性が弱い系列に SARIMA を当てても、その構造は過剰になるかもしれません。
次に、説明しやすさも重要です。
実務では、モデルがなぜその予測をしているのかを、関係者に説明できる必要があります。
そのとき、複雑なモデルが必ずしも有利とは限りません。
さらに、保守しやすさも無視できません。
再学習の手順が複雑すぎないか、モデル更新を継続できるか、といった点も重要です。
つまり、モデル比較では
精度だけでなく、前提の妥当性・解釈可能性・運用しやすさも含めて判断する
必要があります。
今回の月次の小売売上データでは、これらの観点をあわせて見ても SARIMA を選ぶ理由がありました。
しかし、別の系列では ARIMA のほうが適切なことも十分にあります。
大事なのは、モデル名で決めることではなく、系列の性質と用途に応じて選ぶことです。
Conclusion | まとめ
今回は、単変量時系列モデルの代表である ARIMA と SARIMA を取り上げ、月次の小売売上データに対して Python で比較しました。
第5回までで見てきたように、時系列データ分析では、まず非定常性を見分け、系列を整えることが重要です。
ただし、定常化はそれ自体がゴールではありません。定常化した系列を予測や構造理解に使うためには、その次にモデル化が必要になります。
今回の比較では、月次の小売売上データに対しては、ARIMA よりも SARIMA のほうが自然なモデルでした。
予測結果、AIC / BIC、予測誤差、残差診断のいずれを見ても、季節成分を持つ SARIMA のほうがデータの構造に合っていました。
この結果は、季節性がある系列では SARIMA が有力になりやすいことを示しています。
一方で、これは「常に SARIMA を選べばよい」という意味ではありません。季節性が弱い系列や、データ期間が短い系列では、ARIMA で十分なこともあります。
大事なのは、モデル名だけで決めることではなく、
- 系列にどのような構造があるか
- 予測結果はどうか
- 残差にパターンが残っていないか
- 実務で説明・運用しやすいか
をあわせて判断することです。
つまり、単変量時系列モデルの選択では、精度だけでなく、系列の性質と前提の妥当性を見ることが重要です。
次回予告
次回は、1本の系列だけを見る単変量モデルから一歩進んで、複数の系列の関係を同時に扱う多変量時系列モデルを取り上げます。
具体的には、VAR を中心に、単変量モデルとの違いや、どのような場面で多変量モデルが必要になるのかを見ていきます。
References | Pythonコードの全文
今回の記事で書いたPythonコード(Jupyter Notebook)の全文は以下です。ご参考にどうぞ!
コメント