Ciao!みなさんこんにちは!このブログでは主に
(1)pythonデータ解析,
(2)DTM音楽作成,
(3)お料理,
(4)博士転職
の4つのトピックについて発信していきます。
今回は久しぶりのデータ解析のレシピです!
内容自体は先日のお金のレシピで預金金利とインフレ率を比較した記事の分析の詳しい内容の紹介です。
政府統計など、公的統計のcsvデータをプログラミングで扱う際には、文字コードに注意する必要があります。
データ解析では、utf-8という文字コードを使うのが世界標準です。
しかし、日本の公的統計のデータではcp932という文字コードが使われていることが非常に多く、「いつもの感覚」でデータを読み込んでいると正常にデータの読み込みが行われないなどの問題が発生します。
私自身、民間データサイエンティストとしての業務でも私生活でも(笑)政府統計などの日本の公的データを扱います。
文字コード問題に何度もつまづいて来ましたが、スムーズにデータの読み込みができる方法に行き当たりましたので、この記事にまとめておきます。
pythonなどで政府統計などの公的データを扱おうとしている方、扱おうとして正常に読み込みができなくてつまづいている方には、ご一読いただければ幸いです!
Abstract | 日本の公的統計データは文字コード指定で読み込むべし
日本の公的統計のデータをプログラミングで読み込む際には、文字コードをcp932に指定する必要があることが多いです。
文字コードとは、数字や文字をファイルに書き込む際のルールです。
ファイルを読み込むときに、書き込まれたときと異なる文字コードで読み込んでしまうと、文字化けを起こしたりエラーになってしまいます。
世界標準の文字コードはutf-8です。
そのためプログラミングでファイルを読み込む際には、デフォルトではutf-8となっていること多いです。
utf-8が世界標準となっているにもかかわらず、日本政府や日銀などが発行している公的統計データは、cp932という文字コードが使われています。
そのため、文字コードを指定せずutf-8で読み込んでしまうと文字化けしたり、エラーで読み込めなかったりします。
この記事では、私が何度も躓いてきた文字コード問題の解決策をご紹介します!
cp932でコードされているcsvファイルも、ちゃんと文字コードを指定すればスムーズに読み込む事ができます。
一緒にやってみましょう!
Background | 公的統計データと文字コード
日本政府や日銀などが発行している公的統計データは、cp932という文字コードが使われていることがほとんどです。
前回や前々回の記事でダウンロード方法を紹介した、預金金利や消費者物価指数などのデータもcp932というコードが使われています。
文字コードとは、数字や文字などのデータをファイルに書き込むときのルールです。
書き込んだときのルールと読み込むときのルールが一致していないと正常に読み込むことができません。
したがって、プログラミングなどでファイルを読み込むときには、書き込まれたときと同じ文字コードを指定して読み込む必要があるのです。
cp932とは「Microsoft コードページ932」の略称です。
その名の通り、憎きマイクロソフト及び、MS-DOSのOEMベンダ(IBMやNEC)がShift_JISを独自に拡張した文字コードです。憎きWindowsでは標準的に使われている文字コードです。
そのため、例えば憎きMicrosoft Excelでファイルを作ってcsvに出力をしたりすると、不幸なことにcp932でコードされたcsvファイルが作成されてしまうようです。
私の独断的個人の視点からすると、cp932は「日本メーカーのガラケー」のようなかなりガラパゴス化した文字コードのように感じています。
というのも、世界標準の文字コードとしてはutf-8が使われており、pythonなどのコーディングでも(少なくとも私の周りでは)utf-8が使われるためです。
実際、cp932でコードされたcsvファイルを日本の公的統計以外のデータで見たことがありません。民間企業からもらうデータは、日本企業であってもutf-8でコードされていることが多い感覚があります。
普段、特に文字コードを意識せずにutf-8でコーディングをしていて、utf-8でコードされたファイルの読み書きをしている分には全く問題は発生しません。
ところが、公的統計データを読み込むと毎回のように正常に読み込めない問題が発生するのです。
具体的には、
- 数字以外ほとんどすべての文字が文字化けする
- カンマの位置が正しく認識されず、列が正常に読み込まれない
といった問題が発生します。
このような問題が発生したときには、文字コードを疑ってみましょう。
公的統計であったり、日本企業が作成したデータであれば、憎きWindowsのガラパゴスフォーマットcp932が使われている可能性があります。
utf8でコードしてくれればいいのですが、文句ばかり言っていても仕方がないので、この記事で対処法を紹介します!
Method | 文字コードを指定してpd.read_csv()
cp932でコードされたファイルを読み込むときには、ファイル読み込みの関数で文字コードをcp932に指定します。
csvの読み込みであれば、pandasライブラリのread_csv()関数を使う際に文字コードを指定することができます。
私は少し前までは、numpyライブラリのgenfromtxt()を愛用していましたが、文字コードの指定がうまくいかないため、最近はもっぱらread_csv()を使っています。
read_csv()関数はデフォルトでは、utf-8の文字コードでファイルを読み込みます。
cp932でコードされたファイルを読み込むときには、この関数の文字コードを指定する引数に、’cp932’を指定することで正常に読み込むことができます。
以下の例で、その方法を説明します。
消費者物価のデータを読み込む例
まずは、消費者物価のデータを読み込む際の例で方法を紹介します。
前回の記事でダウンロードした以下のデータを読み込んでみます。
次のようにして、pandanのDataFrameとして読み込みを行います。
import pandas as pd
t = pd.read_csv('e-Stat_CPI_monthly_All.csv', header = None, skiprows=10, encoding = 'cp932')
これで、変数tにDataFrameが読み込まれます。
read_csv()関数の文字コード指定
read_csv()の第一引数はファイル名です。
encoding = 'cp932'
としているところで文字コードをcp932に指定しています。
文字コードを指定しないデフォルトの場合、utf-8として読み込まれます。
そのため、cp932でコードされている公的統計などのデータを、文字コード指定なしで読み込んでしまうと、
- エラーとなって読み込めない
- ほとんど文字化けする
といった不具合が起こります。
日本の政府機関や企業が作ったcsvデータが上手く読み込めないときは、文字コードがcp932になっていないか確かめると良いでしょう。
文字コードの簡単な確認方法はこの記事の後半で紹介していますので、最後までお読みください。
read_csv()関数のヘッダー指定
他の引数の
header = None
では、ヘッダーの指定を行っています。
ここではヘッダー情報をDataFrameに読み込まないように’None’を指定しします。
この引数は指定しなくても構いません。
ただし、その場合、最初の行がヘッダーとして指定されます。
このファイルの場合、日本語の文字列が入っていますが、日本語の文字列がヘッダーとなるのは扱いです。なので、あえてヘッダーが入らないように読み込んでいます。
ヘッダーが入らないよう、’header = None’と指定すると、データフレームの各列を
t[0]
と言った具合に、シンプルに参照することができます。日本語文字列のヘッダーが入っていると、[]の中に’0’の代わりに日本語を入力しないといけません。それは面倒なのです。
read_csv()関数のskiprows指定
また、
skiprows = 9
では、最初の9行を読み飛ばす指定を行っています。
‘e-Stat_CPI_monthly_All.csv’というファイルの最初の10行にはデータは格納されていません。
1–9行目にデータソースなどのメタ情報、10行目に日本語のヘッダーが入っています。
‘skiprows = 9’とすることで、このメタ情報が入っている行を読み飛ばしています。
このメタ情報の部分は、10行目以降とは列数が異なります。
なので、読み飛ばしておかないと、エラーになってしまいます。
文字コードを簡単に確認する方法
csvデータが上手く読み込めないときに、文字コードがcp932になっていないか確かめる方法をご紹介します。
Atomなどのエディターでは、表示する際の文字コードを指定できます。
Atomは日本でも利用者の多い便利なコードエディタです。
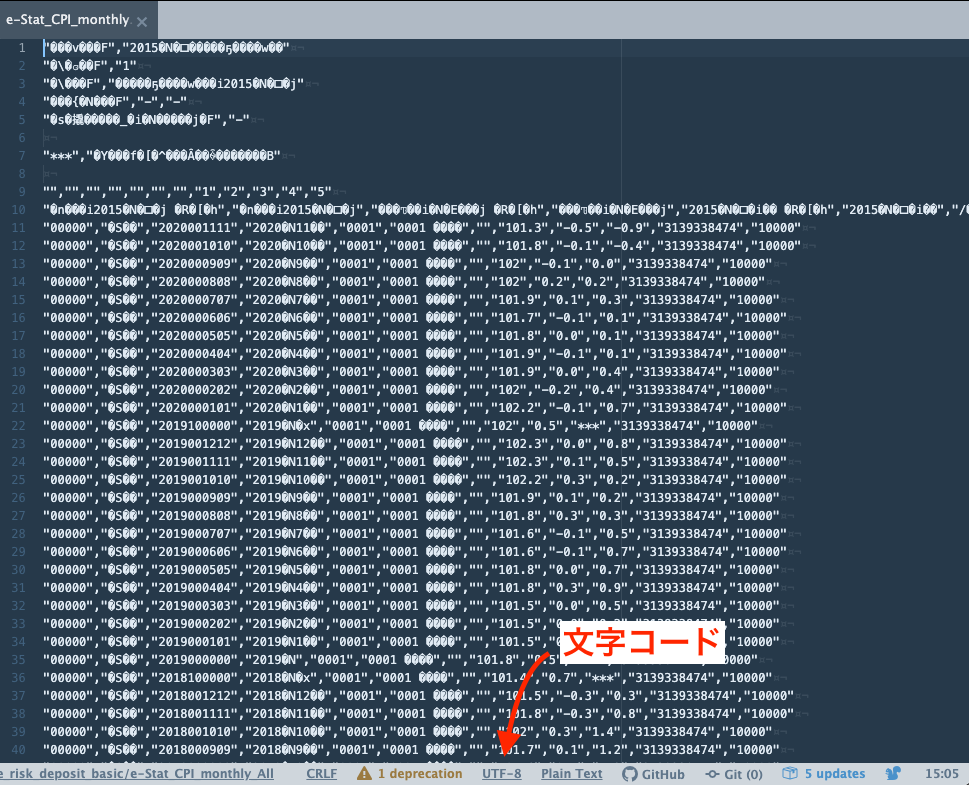
AtomエディタでUTF-8で表示してみる
Atomでcp932を指定してcsvファイルを表示したときに、文字化けせずに正しく表示されるか確かめましょう。
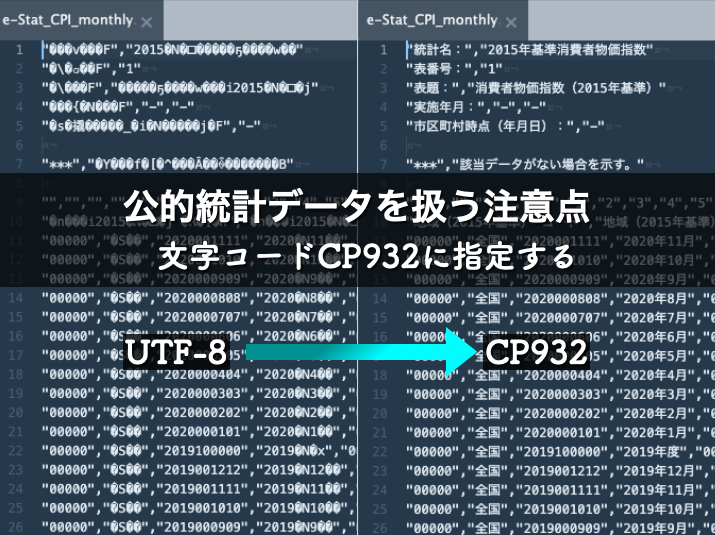
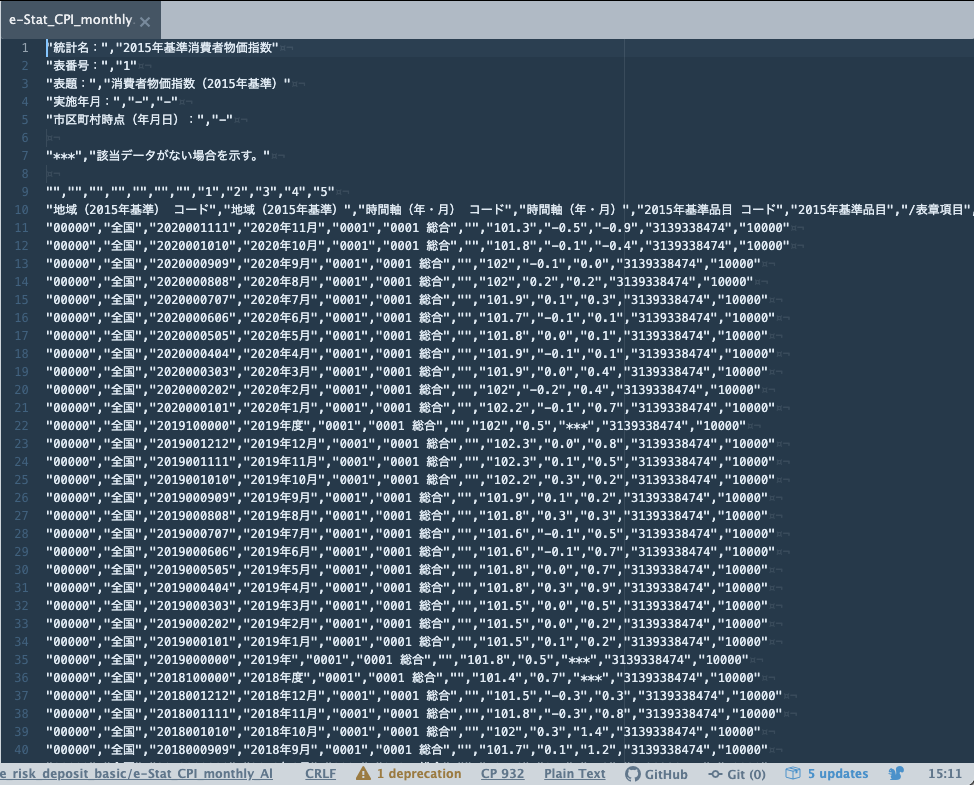
まずは、消費者物価指数のファイル’e-Stat_CPI_monthly_All.csv’をAtomエディタで開いた場合には下図1のように文字化けします。
この文字化けは、ファイルがcp932でエンコードされているにも関わらず、utf-8で読み込んだためです。
AtomエディタでCP932を指定する方法
次に、文字コードにcp932を指定してみます。
以下のように行います。
まず、下図2のように画面下部の文字コード「UTF-8」をクリックします。
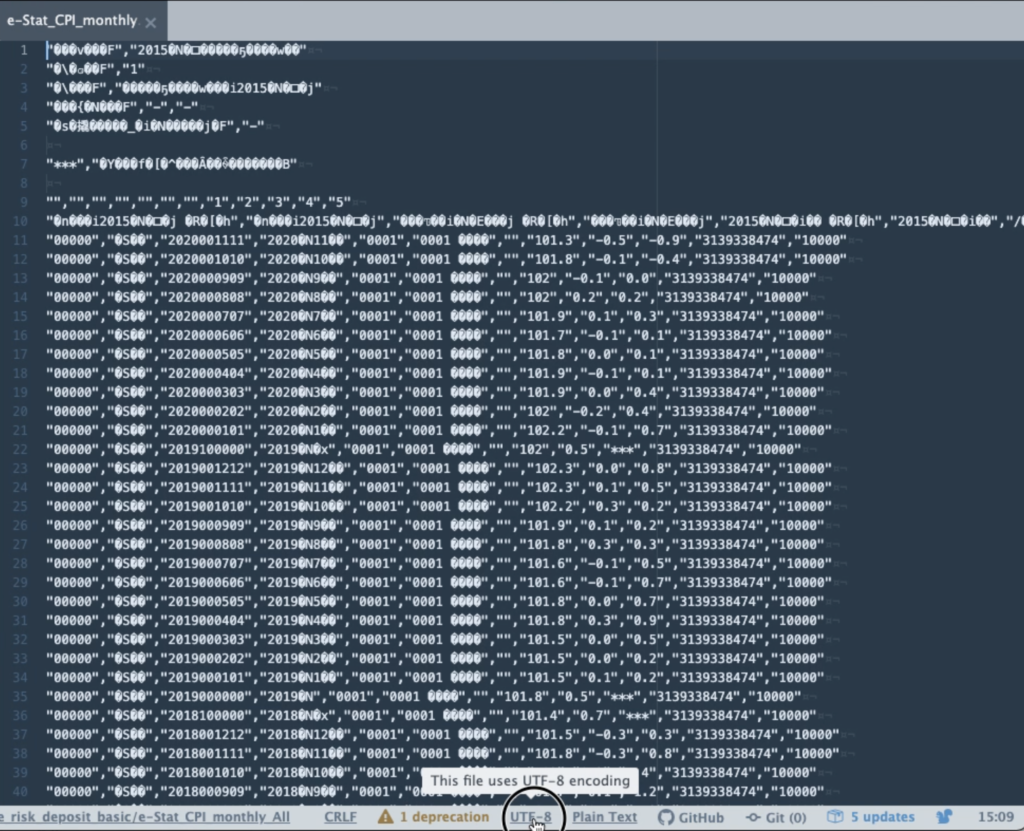
すると、画面上の方に文字コードを選択するウィンドウが表示されます。
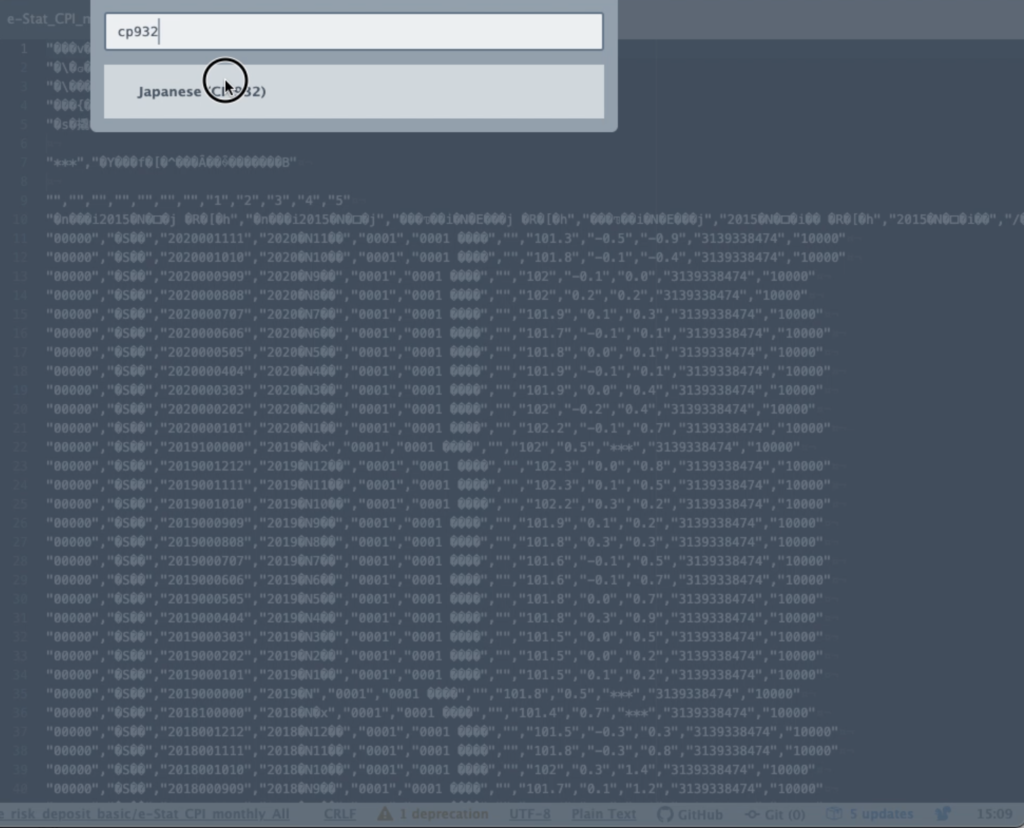
下図3のように、検索窓に’cp932’と入力すると、
Japanese (CP932)
という選択肢が現れるので、それをクリックします。
これで、下図4のように、文字コードがCP932に指定され、文字化けが解消されています。
このファイルがCP932でコードされていることが確認できました。
Result | pythonで公的統計データを分析する例
以前のお金のレシピで預金金利とインフレ率を比較した記事の分析で用いたpythonのコードをご紹介します。
pythonソースコードは以下になりますので、自己責任でご自由にご利用ください。
次の3つのファイルが同じディレクトリ(フォルダ)に存在することが前提となっていますので、こちらもダウンロードしてください。
もしくは、pythonソースコードでinput fileを指定している箇所のファイル名をご自分の環境に合わせて変更してください。
Conclusion | まとめ
最後までご覧いただきありがとうございました!
文字コードを指定しながら、公的統計データをpythonで読み込む方法をご紹介しました!
日本の公的統計のデータは、世界標準のutf-8ではなく、ガラパゴスなcp932の文字コードになっていることが多いです。
pythonなどのプログラミングでは、utf-8を想定している事が多いため、何も考えずにファイルを読み込むと、エラーが出たり、文字化けしてしまうことがあります。
そんなときは、cp932を指定して読み込む方法を試してみてください。
お仕事や私生活でデータ分析をする際に、ぜひお役立てください!
以上、「データ解析のレシピ|政府統計や公的統計を扱うときは文字コードに注意すべし(pythonの場合編)」でした!
またお会いしましょう!Ciao!


コメント