
みなさんこんにちは!このブログでは主に
の4つのトピックについて発信しています。
今回の記事では時系列データの分析について扱います!
このシリーズでは、Pythonを使いながら、時系列データ分析で注意すべきポイントを順番に確認してきました。
第1回では、独立なランダムウォーク同士でも高い相関が出てしまう「偽相関」から始めました。そこから、ADF検定やKPSS検定による定常性の確認、差分・トレンド除去・季節調整による定常化、ARIMA・SARIMA・VARといったモデルの使い分けへと進んできました。
最終回となる今回は、これまでの記事で扱ってきた内容を一つの流れとして整理します。偽相関、定常化、モデル選択、評価、実務判断への接続までを、時系列データ分析の「道しるべ」として振り返ります。
この記事を読むことで、これまで扱ってきた偽相関、定常性、定常化、モデル選択、評価といったテーマが、時系列分析の中でどのようにつながっているのかを整理できます。時系列分析を学ぶなかで、どの論点をどの順番で確認すればよいのか、次にどのようなテーマへ進めばよいのか見通しが付きます。
Abstract | 系列理解からモデル選択までの全体を押さえる
時系列分析は、系列の構造を理解し、その性質に合った前処理とモデルを順番に選んでいく分析です。トレンド、季節性、外れ値、構造変化、非定常性を確認することで、差分を取るべきか、トレンドを除去すべきか、季節性を明示的に扱うべきかが見えてきます。
モデル選択も、データの性質と分析目的に応じて考える必要があります。単変量の動きを見るならARIMA、季節性を含めて扱うならSARIMA、複数系列の関係を見るならVARというように、モデルの位置づけは「何を知りたいのか」によって変わります。
本記事では、偽相関、定常性、定常化、モデル選択、評価、実務判断への接続までを、時系列データ分析を進めるための一つの流れとして整理します。どの段階で何を確認し、どの順序で分析結果を判断するかを理解することで、時系列分析全体の流れを押さえます。
Data | 偽相関からモデル選択までの流れ
ここまでの8回では、時系列データ分析に必要な考え方を順番に確認してきました。ランダムウォーク、ADF検定、KPSS検定、差分、トレンド除去、季節調整、ARIMA、SARIMA、VARなどを扱ってきましたが、全体として見ると一つの流れがあります。
このシリーズは、「時系列データをそのまま分析してよいのか」を疑うところから始まり、「データの性質を確認し、必要な前処理を行い、目的に応じたモデルを選び、結果を判断に使えるか確認する」という流れになっています。ここでは、その流れを4つの段階に分けて振り返ります。
偽相関に気づく
↓
定常性を確認する
↓
必要に応じて定常化する
↓
問いに応じてモデルを選ぶ
↓
評価し、判断に接続する
この流れを頭に置いておくと、各回で扱った内容の位置づけが見えやすくなります。第1回から第8回までの内容を、時系列分析を進めるための一連の判断プロセスとして整理していきます。
1. 偽相関と非定常性に気づく
最初に確認したのは、時系列データでは見かけ上の関係が生じやすいという点です。
第1回では、互いに独立なランダムウォーク同士でも、高い相関が出ることを確認しました。これは、時系列データを通常の相関分析や回帰分析にそのままかけると、実際には関係がない系列同士にも「関係がある」ように見えてしまう可能性を示しています。
この問題の背景にあるのが、非定常性です。
平均や分散、自己相関構造が時間とともに変化する系列では、観測値同士が時間方向に強く依存します。そのため、通常の統計分析で前提とする独立性や安定した分布構造が崩れやすくなります。
時系列分析の出発点は、モデルを当てることではなく、「このデータをそのまま分析してよいのか」を疑うことです。偽相関に気づくことは、そのための最初の入口になります。
2. 定常性を確認し、定常化で土台を整える
次に扱ったのが、定常性の確認です。
第2回と第3回では、ADF検定やKPSS検定を使いながら、時系列データが定常かどうかを確認しました。ADF検定は単位根の有無を確認するために使われ、KPSS検定は定常性そのものを帰無仮説として確認する検定です。
定常性の確認では、グラフで系列の形を見たうえで、複数の観点から系列の性質を確認することが重要です。検定結果は判断の手がかりになりますが、実際には、トレンドの有無、季節性、データの頻度、サンプルサイズなども含めて考える必要があります。
非定常性が確認された場合には、必要に応じて定常化を行います。
第4回と第5回では、差分、トレンド除去、季節調整などの方法を確認しました。差分は水準の変化を見る方法であり、トレンド除去は長期的な上昇・下降傾向を取り除く方法です。季節調整は、月次や四半期データに含まれる周期的な変動を扱うために使います。
定常化は、後続のモデル化や解釈をしやすくするための前処理です。何を取り除き、何を残すのかによって、分析結果の意味は変わります。そのため、系列の性質と分析目的を結びつけて、どの処理を行うかを考える必要があります。
3. ARIMA・SARIMA・VARを問いに応じて選ぶ
データの性質を確認し、必要な前処理を行った後で、モデル選択に進みます。
第6回では、単変量時系列モデルとしてARIMAとSARIMAを扱いました。ARIMAは、過去の値や誤差項を使って単一系列の動きを表すモデルです。季節性を明示的に扱いたい場合には、SARIMAが候補になります。
たとえば、季節性が弱い系列に無理にSARIMAを使う必要はありません。一方で、月次売上や季節変動のある経済データのように、周期的な動きが明確な場合には、SARIMAの方が自然な選択肢になります。
第7回では、複数系列の関係を見るためにVARを扱いました。VARでは、複数の時系列データを同時に使い、それぞれの系列が過去の自分自身や他の系列とどのように関係しているかを確認できます。
ARIMA、SARIMA、VARは、分析したい問いに応じて使い分けるモデルです。
単一系列の動きを予測したいのか、季節性を含めて扱いたいのか、複数系列の相互関係を見たいのかによって、適したモデルは変わります。モデル選択では、手法名から入るのではなく、分析したい問いから逆算することが重要です。
4. 評価・解釈・実務判断につなげる
モデルを当てた後には、その結果をそのまま受け入れるのではなく、評価と解釈を行います。
第6回以降では、AICやBIC、予測誤差、残差診断などを使ってモデルを比較しました。見かけ上の当てはまりがよくても、残差に自己相関が残っていたり、予測誤差が実務上許容できなかったりする場合、そのモデルを判断に使うのは危険です。
また、時系列モデルで得られる結果は、基本的には過去のパターンにもとづく予測や関係の記述です。予測できることと、原因を説明できることは同じではありません。
たとえば、ある系列が別の系列に先行して動いているように見えても、それだけで因果関係があるとは言えません。業務判断に使う場合には、分析結果がどの意思決定に対応しているのか、どの範囲まで主張してよいのかを確認する必要があります。
第8回では、こうした点を実務でよくある課題として整理しました。
最終的に重要なのは、系列の構造を確認し、前処理の意味を理解し、目的に合ったモデルを選び、結果を評価し、どの判断に使えるのかを確認することです。モデルの精度の良し悪しを見るだけでは不十分です。
この流れを押さえることで、時系列分析は単なるモデル適用ではなく、データから判断につなげるための一連のプロセスとして扱えるようになります。
Method | 自分の時系列データに向き合うための地図
ここまでの流れを踏まえると、時系列データ分析は次のような順序で進めると整理しやすくなります。
| 段階 | 確認すること | 関係するテーマ | 次に考えること |
|---|---|---|---|
| 1. 系列の構造を見る | トレンド、季節性、外れ値、構造変化 | 可視化、系列理解 | そのまま分析してよいか |
| 2. 定常性を確認する | 平均・分散・自己相関構造が安定しているか | ADF検定、KPSS検定 | 定常化が必要か |
| 3. 定常化の方針を決める | 差分、トレンド除去、季節調整のどれが自然か | 定常化、前処理 | 何を取り除き、何を残すか |
| 4. モデルを選ぶ | 単変量か、多変量か、季節性を含むか | ARIMA、SARIMA、VAR | 問いに合ったモデルか |
| 5. 結果を評価する | 残差、予測誤差、情報量基準、解釈可能性 | AIC/BIC、残差診断、予測評価 | 結果を判断に使えるか |
この表は、自分のデータを見たときに、「いま何を確認しているのか」「次に何を判断すべきか」を整理するための地図です。プロット、検定、定常化、モデル選択、評価を一つの流れとして見ることで、データの性質と分析目的に合った判断をしやすくなります。
1. 系列の構造を見る
最初に行うのは、系列の構造を観察することです。
時系列データでは、平均値だけを見ても全体像は分かりません。時間とともに上昇・下降しているのか、一定の周期で動いているのか、一部の時点だけ大きく外れているのか、途中で構造が変わっていないかを確認します。
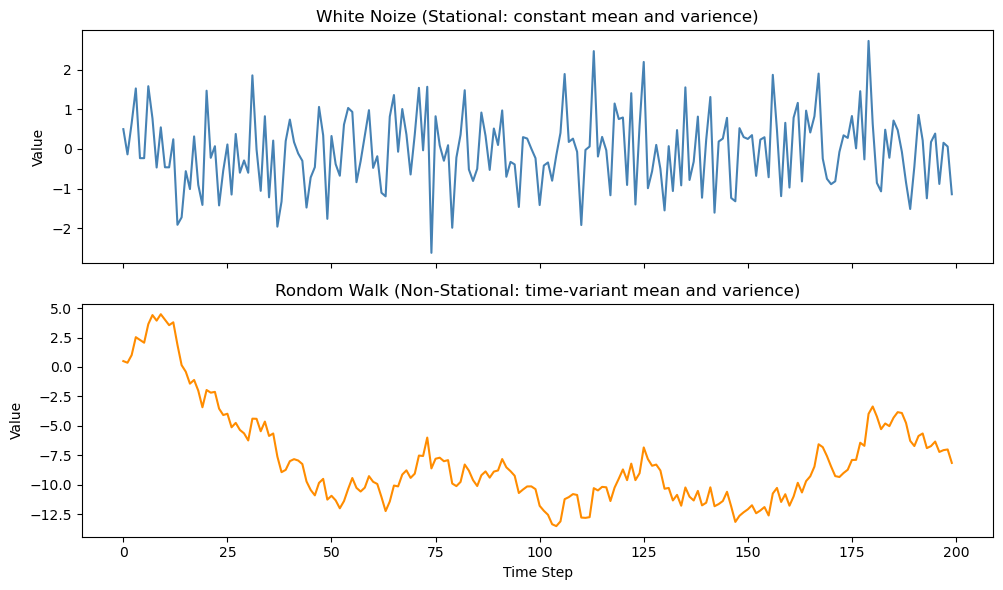
この段階では、いきなり検定やモデルに進むよりも、まずプロットすることが重要です(下図1)。折れ線グラフを描くことで、トレンド、季節性、外れ値、急な水準変化などが見えやすくなります。
ここで見えてきた構造が、その後の分析方針を決める出発点になります。
たとえば、明らかな上昇トレンドがある系列であれば、そのまま相関分析や回帰分析に使うことには注意が必要です。月次データで毎年同じような山と谷が見える場合には、季節性を考慮する必要があります。特定の時期を境に水準が変わっている場合には、構造変化の可能性も考える必要があります。
2. 定常性を確認する
系列の構造を見たら、次に定常性を確認します。
定常性は、時系列データを分析するうえでの基本的な前提を確認するための視点です。平均や分散、自己相関構造が時間を通じて安定しているかを確認することで、その系列をどのように扱えばよいかが見えてきます。
このシリーズでは、ADF検定とKPSS検定を使って定常性を確認しました。
ADF検定では、単位根を持つ非定常系列かどうかを確認します。一方、KPSS検定では、系列が定常であるという前提を置いて確認します。両者は見ている仮説が異なるため、組み合わせて使うことで、系列の性質をより多面的に確認できます。
検定は、系列の性質を確認するための補助線です。実際には、グラフで見た構造、データの生成背景、サンプルサイズ、周期性の有無なども含めて考える必要があります。
3. 定常化の方針を決める
非定常性が確認された場合には、必要に応じて定常化を行います。
定常化では、データに含まれるどの構造を取り除き、どの構造を残すのかを考えます。差分を取れば、水準そのものではなく変化量に注目することになります。トレンド除去を行えば、長期的な上昇・下降傾向を取り除いたうえで短期的な変動を見ることになります。季節調整を行えば、周期的な変動を取り除いた系列を確認できます。
どの方法を選ぶかは、分析目的によって変わります。
たとえば、株価の水準そのものよりも日々の変化を見たい場合には、差分やリターンを見る方が自然です。長期的に成長している経済指標の短期変動を見たい場合には、トレンド除去が役立つことがあります。月次売上の基調を確認したい場合には、季節調整が有効です。
定常化では、処理後の系列が何を表しているのかを確認することが重要です。差分、トレンド除去、季節調整のいずれを選ぶかによって、分析結果として解釈できる内容も変わります。
4. モデルと評価方法を決める
定常化の方針が決まったら、分析目的に応じてモデルを選びます。
単一の系列について、過去の値や誤差項を使って将来の動きを予測したい場合には、ARIMAが候補になります。季節性を明示的に扱いたい場合には、SARIMAが候補になります。複数の系列の関係を同時に扱いたい場合には、VARが候補になります。
ここで重要なのは、モデル名から分析を始めるのではなく、問いからモデルを選ぶことです。
同じデータでも、「この系列を予測したい」のか、「季節性を含めて予測したい」のか、「他の系列との関係を見たい」のかによって、適したモデルは変わります。
また、モデルを選ぶときには、評価方法もあわせて考えます。AICやBICのような情報量基準は、モデル間比較の参考になります。予測誤差は、実際の予測性能を見るために重要です。残差診断は、モデルが捉えきれていない構造が残っていないかを確認するために使います。
モデルを選ぶことと、モデルを評価することは、セットで考える必要があります。
5. 判断に使える結果か確認する
最後に、得られた分析結果をどの判断に使えるのかを確認します。
時系列分析の結果は、予測値、係数、残差、誤差指標、インパルス応答など、さまざまな形で出てきます。しかし、それらの数値をそのまま業務判断に使えるとは限りません。
確認すべきなのは、その結果が分析目的に対応しているかです。
予測モデルであれば、予測誤差が実務上許容できる範囲にあるかを確認します。複数系列の関係を見るモデルであれば、その関係をどの範囲まで解釈してよいのかを確認します。意思決定に使う場合には、その結果が具体的にどの判断を支えるのかを明確にします。
特に、予測関係と因果関係の区別は重要です。
ある系列が別の系列に先行して動いているように見えても、それだけで原因と結果の関係があるとは言えません。時系列モデルから分かることと、施策として介入してよいことは分けて考える必要があります。
このように、時系列分析では、系列の構造を見るところから、定常性の確認、定常化、モデル選択、評価、実務判断への接続までが一つの流れになります。
自分の時系列データに向き合うときには、いまどの段階にいるのかを確認しながら進めることが重要です。そうすることで、手法だけを先に選んでしまうのではなく、データの性質と分析目的に合った判断がしやすくなります。
Result | 分析結果を使う前の最終確認
最後に、時系列分析の結果を判断に使う前に確認しておきたい項目を整理します。ここまで見てきたように、時系列分析では、データの構造、定常性、前処理、モデル選択、評価、解釈がつながっています。どこか一つだけを見るのではなく、分析結果を使う前に全体を確認することが重要です。
- 系列をプロットし、トレンド・季節性・外れ値・構造変化を確認したか
- 相関や回帰の前に、非定常性による偽相関の可能性を考えたか
- ADF検定やKPSS検定などを使い、定常性を確認したか
- 差分、トレンド除去、季節調整などの処理を、分析目的に合わせて選んだか
- 処理後の系列が何を表しているのかを説明できるか
- ARIMA・SARIMA・VARなどのモデルを、データの構造と問いに応じて選んだか
- AIC/BIC、予測誤差、残差診断などを使ってモデルを評価したか
- 残差に自己相関や取り残した構造が残っていないか
- 予測関係と因果関係を区別して解釈しているか
- 分析結果が、どの実務判断を支えるものなのかを明確にしたか
このチェックリストは、分析結果を使う前に見落としやすい論点を確認するためのものです。系列の性質を確認し、必要な前処理を行い、問いに合ったモデルを選び、結果の限界を理解することで、分析結果を判断に使いやすくなります。
Discussion | 次に学ぶとよいテーマ
このシリーズでは、偽相関、定常性、定常化、ARIMA・SARIMA・VARといった基本的な考え方を扱ってきました。ここまで理解できると、時系列データをそのまま相関分析や回帰分析にかける危険性、モデルを使う前に確認すべき前提、単変量モデルと多変量モデルの違いが見えやすくなります。
一方で、実務で扱う時系列データには、さらに複雑な構造が含まれることがあります。トレンドや季節性が時間とともに変わる、外部要因の影響を受ける、階層構造を持つ、施策やイベントによって構造が変わる、といったケースです。ここでは、このシリーズの次に学ぶテーマとして、いくつかの方向性を整理します。
1. 状態空間モデルで、観測できない構造を扱う
次に学ぶテーマとして特に重要なのが、状態空間モデルです。状態空間モデルでは、観測された時系列データの背後にあるトレンド、季節性、ノイズ、潜在的な状態を分けて考えることができます。
たとえば、売上データを見たときに、観測値そのものは「トレンド」「季節性」「一時的なノイズ」「キャンペーンなどの影響」が重なった結果として現れます。状態空間モデルを使うと、こうした観測値の背後にある要素を分解しながら、時間とともに変化する構造を柔軟に扱いやすくなります。
このシリーズで扱った定常化や季節調整は、観測された系列を分析しやすい形に整えるための考え方でした。状態空間モデルに進むと、系列に含まれる構造を明示的にモデル化しながら、観測できない状態を推定する方向へ広がります。
2. 外生変数・構造変化・階層性を扱う
時系列データは、自分自身の過去の値だけで動いているとは限りません。広告費、金利、気温、イベント、制度変更、競合要因など、外部の変数が系列に影響していることがあります。そのような場合には、外生変数を含むモデルを学ぶと、分析の幅が広がります。
たとえば、SARIMAXのようなモデルでは、季節性を含む時系列構造に加えて、外部要因を説明変数として組み込むことができます。単に過去の値から予測するだけでなく、「どの外部要因を考慮すると予測や解釈が改善するか」を検討しやすくなります。
また、実務では構造変化も重要です。コロナ禍、価格改定、規制変更、サービス仕様の変更などによって、過去と現在でデータの生成構造が変わることがあります。さらに、店舗別売上、地域別需要、商品カテゴリ別販売数のように、階層構造を持つ時系列データを扱うこともあります。こうしたテーマに進むと、時系列分析をより実務データに近い形で扱えるようになります。
3. 機械学習・深層学習による時系列予測へ進む
時系列予測では、機械学習や深層学習を使う方法もあります。勾配ブースティング、ランダムフォレスト、ニューラルネットワーク、RNN、LSTM、Transformer系のモデルなどは、複雑な非線形関係や多数の特徴量を扱う場面で候補になります。
機械学習を使う場合でも、時系列データとしての性質を確認する視点は重要です。ラグ特徴量、移動平均、季節性を表す特徴量、イベントフラグなどをどのように作るかによって、モデルの性能や解釈は大きく変わります。また、学習データと検証データの分け方も、通常のランダム分割ではなく、時間の順序を意識した検証にする必要があります。
このシリーズで扱った定常性、季節性、残差、予測誤差の考え方は、機械学習モデルを使う場合にも土台になります。モデルが高度になっても、データの構造を理解し、評価方法を適切に設計することが重要です。
4. 因果推論と意思決定へ広げる
もう一つ重要なのが、因果推論との接続です。時系列分析では、ある系列が別の系列に先行して動くことがあります。しかし、先行して動くことと、原因になっていることは同じではありません。
実務では、「広告を増やしたから売上が増えたのか」「施策によって解約率が下がったのか」「価格変更が需要に影響したのか」といった問いがよく出てきます。これらは予測の問いではなく、介入の効果を知りたい問いです。そのため、時系列モデルだけでなく、因果推論の考え方を組み合わせる必要があります。
時系列データを使った因果推論では、介入前後の比較、差分の差分法、合成コントロール法、構造時系列モデルなどが候補になります。重要なのは、「予測できるか」と「施策として動かしてよいか」を分けて考えることです。
このシリーズで学んだ内容は、因果推論に進むための前提にもなります。非定常性や構造変化を見落としたまま介入効果を解釈すると、施策の効果ではなく、もともとのトレンドや外部要因を効果として見てしまう可能性があります。時系列分析の基本を押さえておくことで、意思決定に使う分析の前提をより丁寧に確認できるようになります。
Conclusion | 時系列分析の流れを一つの地図として持つ
このシリーズでは、偽相関、定常性、定常化、モデル選択、評価、実務判断への接続までを、Pythonで実証しながら確認してきました。ランダムウォーク同士の偽相関から始まり、ADF検定・KPSS検定による定常性確認、差分・トレンド除去・季節調整、ARIMA・SARIMA・VARによるモデル化へと進みました。
時系列分析で重要なのは、目の前の系列がどのような構造を持っているのかを確認し、その性質に応じて前処理とモデルを選ぶことです。トレンドがあるのか、季節性があるのか、複数系列の関係を見る必要があるのかによって、取るべき分析の進め方は変わります。
このシリーズで扱った内容は、状態空間モデル、外生変数付きモデル、機械学習による時系列予測、因果推論などへ進むための土台になります。自分の時系列データに向き合うときは、個別の手法だけでなく、系列理解からモデル選択、評価、判断への接続までを一つの地図として持っておくことが大切です。
本シリーズが、時系列データ分析を進めるときの道しるべになれば幸いです。
コメント