
Ciao!みなさんこんにちは!このブログでは主に
(1)pythonデータ解析,
(2)DTM音楽作成,
(3)お料理,
(4)博士転職
の4つのトピックについて発信しています。
今回はPythonデータ解析、\(a^{x}\)を高速に計算する方法を紹介します。\(a^{x}\)(aのx乗)の計算は統計学やデータ解析で頻出の計算です。Pythonでは、a**xやnp.power(a, x)など、実装方法がいくつかあるので、いくつかの実装方法について計算速度を比較します。さらに、前回記事「NumPyレシピ | np.exp(x)はe**xよりも2倍ほど高速!」では、np.exp(x)が高速であることがわかったので、np.expを使ってa**xを計算する方法も取り入れます!
この記事を読めば、データサイエンスで頻出の\(a^{x}\)を高速に計算する方法がわかります。
この記事はこんな人におすすめ
- Pythonでデータ解析をしている
- Numpyで\(a^{x}\)を高速に計算したい
Abstract | aが単一数値であることが確実でない限りa**xでOK
Pythonでは、一つの計算を様々な方法で実現することができ、計算結果は同じでも計算速度が方法によって異なります。データサイエンスでは、大きな配列xに対して\(a^{x}\)の計算を行う場面が多くあり、変数aが配列の場合もあります。\(a^{x}\)をコーディングするる方法として、a**x、np.float_power(a, x)など複数の選択肢が存在します。
そこで、今回は大きな配列xに対して\(a^{x)\)の計算を行う場面で、3つの実装方法の計算速度を測定しました。結果、
aが単一の数値の場合:np.exp(x * np.log(a))が高速aが配列の場合: どの手法でも同程度の速度
であることがわかりました。aが単一の数値であることが確実な場合にはnp.exp(x * np.log(a))を使う価値がありそうですが、そうでない場合にはコーディングの煩雑さを考えてa**xで十分と考えます。
Pythonで\(a{x}\)の計算の高速化に興味がある方はぜひ最後までご覧ください!
Background | やりたいこと
単一のfloat型変数または配列aがあるとき、サイズの大きな配列xについて、各要素の\(a^{x}\)を計算するということを行います。例えば、aが単一のfloat、xが10000 x 10000の2次元配列(要素が合計1億個)であるとき、1億個の\(a^{x}\)をどのように計算すれば高速かを考えていきます。
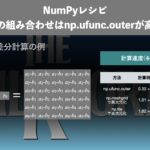
前回記事からの考察 | np.exp(x)を使って`a**x`を計算する方法
前回記事「NumPyレシピ | np.exp(x)はe**xよりも2倍ほど高速!」では、\(e^{x}\)の計算ではnp.exp(x)が高速であることがわかりました。そこで、今回はnp.exp(x)を使って\(a^{x}\)を計算する方法も取り入れます。
\(a^{x}\)の計算にnp.exp(x)を使うには以下のようにします。\(y = a^{x}\)の両辺の自然対数(\(\ln\))を取って、\(y = e^{X}\)の形に変数変換します。
$$
\begin{align}
y &= a^{x} \\
\ln(y) &= x \ln(a) \\
y &= \exp(x \ln(a))
\end{align}
$$
このように、\(a^{x} = \exp(x \ln(a))\)であることがわかります。したがって、
np.exp(x * np.log(a))
によって\(a^{x}\)を計算することができます。
配列計算のポイント | NumPyに対応した方法を使う
配列計算の高速化でポイントとなるのは、NumPyに対応した方法を使うことです。NumPyに対応した方法であれば、NumPy配列に対してforループなどを使わずに高速計算できます。
NumPyに対応した\(a^{x}\)の計算方法の例
\(a^{x}\)の計算であれば、
a**xnp.float_power(a, x)np.exp(x * np.log(a))
といった方法はNumPyに対応しています。すなわち、変数xやaはNumPy配列として定義されていてもそのまま計算できます。
NumPyに対応していないExponentialの計算方法の
NumPyに対応していない計算方法の例としてmathライブラリの関数「math.pow(a, x)」が挙げられます。前回記事「NumPyレシピ | np.exp(x)はe**xよりも2倍ほど高速!」で、NumPy非対応の方法が非常に遅いことがわかっているので、今回はこの方法は使いません。
Method | exp(x)を計算する3手法で計算速度を測定する
さて、実際にJupyter Notebookでコードを書き、NumPy対応の3手法
a**xnp.float_power(a, x)np.exp(x * np.log(a))
を実装し、計算速度を測定していきます。
準備 | ライブラリ、変数x、関数群
まずは準備として、
- 必要なライブラリのインポート
- 配列変数
xの準備 - 計算に用いられる関数群の準備
をしていきます。
ライブラリのインポート
まずは必要なライブラリをインポートします。Jupyter Notebookのコードセルで以下を実行します。
import numpy as np
import time当然NumPyを使うのでnpとしてインポートしておきます。Timeライブラリは計算時間の測定に使います。
配列変数xの作成
サイズの大きな配列xを作っておきます。ここでは[10000, 10000]の2次元配列とし、値は標準正規分布に従うランダムな数値としておきます。以下を実行して変数xを作成しておきます。
# define array: x
x = np.random.normal(0, 1, size=(10000, 10000))
関数群の準備
\(a^{x}\)の計算
a**xnp.float_power(a, x)np.exp(x * np.log(a))
を実行する関数と時間を測定する関数を用意しておきます。以下を実行します。
# a**x
def func_pow(a, x):
return a**x
# np.power
def func_np_float_power(a, x):
return np.float_power(a, x)
# np.exp
def func_np_exp(a, x):
return np.exp(x * np.log(a))
# measure runtime
def mes_run_time(fnc, *args, n=5):
# time array
t_dat = np.zeros([n])
# loop for n
for i in range(n):
# get start UNIX time
t0 = time.time()
# run process
ret = fnc(*args)
# get end time
t1 = time.time()
# to array
t_dat[i] = (t1-t0)
# - show result - #
print(' results:', ret.ravel()[:3])
# - avg, std - #
t_avg = np.average(t_dat)
t_std = np.std(t_dat)
# - verb - #
print(' delta t [s] = %f +/- %f' % (t_avg, t_std))
# - end - #
return t_avg, t_stdこのセルの前半部分では\(a^{x}\)を計算するための3つの関数
func_pow(a, x)func_np_float_power(a, x)func_np_exp(a, x)
を定義しています。このように関数を定義しておくことで、時間を測定する関数mes_run_time(fnc, *args, n=5)の引数fncに渡すことができます。3つの関数すべて同じ引数aとxを取る形になっていることがぽんとです。
セルの後半部分では時間を測定する関数mes_run_time(fnc, *args, n=5)を定義しています。n回測定したときの計算時間の平均と標準偏差を求めます。
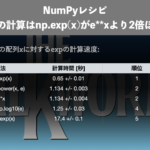
\(a^{x}\)の計算時間の測定1: \(a\)が単一の数値の場合
まずは\(a\)が単一のfloat数値の場合について、前述の3手法
a**xnp.float_power(a, x)np.exp(x * np.log(a))
を使って、\(a^{x}\)の計算時間を測定していきます。
\(a\)の定義(単一数値の場合)
まずは変数aを定義します。aは範囲(0,1)の一様分布に従うランダムなfloat値として定義します。以下を実行します。
# define a
a = np.random.uniform()
print('a =', a)ランダムなので実行結果は実行するたびに変化します。
a**xの実行時間: 1.13 \(\pm\) 0.02 秒
a**xの実行時間を測定します。以下を実行します。
# a**x
_ = mes_run_time(func_pow, *(a, x), n=5)実行結果は
results: [13.56873538 0.73959717 0.01794254] delta t [s] = 1.132999 +/- 0.016939
となりました。計算にかかった時間は1.13 \(\pm\) 0.02 秒です。
この結果は実行環境や実行時の状況によって変化するのでご留意ください。また、resultsに表示される結果もxによって変化します。配列xがランダムな値なので、xを作成するたびに変化します。だだし、同じxを使っている限りresultsの表示は変化しないので、他の手法でも同じ結果になることを確認できます。
np.float_power(a, x)の計算時間: 1.130 \(\pm\) 0.005 秒
np.float_power(a, x)の実行時間を測定します。以下を実行します。
# np.power
_ = mes_run_time(func_np_float_power, *(a, x), n=5)実行結果は
results: [13.56873538 0.73959717 0.01794254] delta t [s] = 1.129863 +/- 0.004892
となりました。計算にかかった時間は1.130 \(\pm\) 0.005 秒なので、a**xと同じという結果です。
np.exp(x * np.log(a))の計算時間: 0.737 \(\pm\) 0.005 秒
最後に変則的な方法、np.exp(x * np.log(a))の実行時間を測定します。以下を実行します。
# np.exp
_ = mes_run_time(func_np_exp, *(a, x), n=5)結果は
results: [13.56873538 0.73959717 0.01794254] delta t [s] = 0.737313 +/- 0.004533
となりました。計算にかかった時間は0.737 \(\pm\) 0.005 秒なので、前述の2手法よりも高速です。前回記事「NumPyレシピ | np.exp(x)はe**xよりも2倍ほど高速!」で紹介した通り、np.exp()が高速なので、今回もnp.exp()を使った方法が高速でした。
\(a^{x}\)の計算時間の測定1: \(a\)が配列の場合
続いて\(a\)が配列の場合についても同様に
a**xnp.float_power(a, x)np.exp(x * np.log(a))
の3手法について\(a^{x}\)の計算時間を測定していきます。
\(a\)の定義(単一数値の場合)
変数aを配列として定義します。aは範囲(0,1)の一様分布に従うランダムな値を持つ配列で、サイズは配列xと同じとします。以下を実行します。
# define a as array
a = np.random.uniform(size=np.shape(x))
print(' a =', a.ravel()[:3])ランダムなので実行結果は実行するたびに変化します。
a**xの実行時間: 1.229 \(\pm\) 0.007 秒
a**xの実行時間を測定します。以下を実行します。
# a**x
_ = mes_run_time(func_pow, *(a, x), n=5)実行結果は
results: [1.68806693 0.85068284 0.40435143] delta t [s] = 1.229374 +/- 0.007031
となりました。計算にかかった時間は1.229 \(\pm\) 0.007 秒です。aが単一数値のときに比べてわずかに遅いですが、誤差の不定性を考えるとほぼ同程度と考えて良いでしょう。
np.float_power(a, x)の計算時間: 1.193 \(\pm\) 0.009 秒
np.float_power(a, x)の実行時間を測定します。以下を実行します。
# np.power
_ = mes_run_time(func_np_float_power, *(a, x), n=5)実行結果は
results: [1.68806693 0.85068284 0.40435143] delta t [s] = 1.193077 +/- 0.009350
となりました。計算にかかった時間は1.193 \(\pm\) 0.009 秒なので、a**xとほとんど同じで、aが単一の数値のときともほぼ同じです。
np.exp(x * np.log(a))の計算時間: 0.737 \(\pm\) 0.005 秒
最後に変則的な方法、np.exp(x * np.log(a))の実行時間を測定します。以下を実行します。
# np.exp
_ = mes_run_time(func_np_exp, *(a, x), n=5)結果は
results: [1.68806693 0.85068284 0.40435143] delta t [s] = 1.202207 +/- 0.014506
となりました。計算にかかった時間は1.20 \(\pm\) 0.01 秒となりました。aが配列の場合は、前述の2手法と同じ計算時間となりました。aが単一の数値のとき(0.737 \(\pm\) 0.005 秒)と比べて遅くなりました。おそらく、np.log(a)の計算に時間がかかる分、np.exp()で高速化される恩恵がなくなってしまったと考えられます。
Result | 3手法の\(a^{x}\)の計算速度の測定結果まとめ
サイズの大きな配列xについて\(a^{x}\)を計算する方法3つの計算速度の測定結果をまとめると以下のようになります。
\(a\)が単一の数値の場合: np.exp()を使う方法が高速
aが単一の数値の場合、\(a^{x}\)の計算速度は以下のようになりました。
| # | 方法 | 計算速度 [秒] | 順位 |
| 1 | a**x | 1.13 \(\pm\) 0.02 | 2 |
| 2 | np.float_power(a, x) | 1.130 \(\pm\) 0.005 | 2 |
| 3 | np.exp(x * np.log(a)) | 0.737 \(\pm\) 0.005 | 1 |
この結果から、np.exp(x * np.log(a))が一番高速であることがわかります。
\(a\)が配列の場合: 3手法とも同程度の速度
aが配列の場合、\(a^{x}\)の計算速度は以下のようになりました。
| # | 方法 | 計算速度 [秒] | 順位 |
| 1 | a**x | 1.229 \(\pm\) 0.007 | 1 |
| 2 | np.float_power(a, x) | 1.193 \(\pm\) 0.009 | 1 |
| 3 | np.exp(x * np.log(a)) | 1.20 \(\pm\) 0.01 | 1 |
この結果から、どの手法でも同程度の計算速度となることがわかります。np.exp()を用いた方法では、np.log(a)の計算時間でnp.exp()によって高速化された恩恵が消えてしまったと考えられます。
今回作成したPythonコードのサンプル
今回書いたPythonコードを載せます。参考にしてください。
Conclusion | まとめ
最後までご覧頂きありがとうございます!
Pythonで、サイズの大きな配列xについて、\(a^{x}\)を高速に計算する方法をご紹介しました!
Pythonでは、一つの計算を様々な方法で実装することができます。計算結果は同じでも計算速度は実装方法によって差があり、対象が配列なのか一つの値なのかなど、条件によっても変化します。今回\(a{x}\)については、
aが単一の数値の場合:np.exp(x * np.log(a))が高速aが配列の場合: どの手法でも同程度の速度
ということががわかりました!データサイエンスなど統計学の計算や科学計算では\(a^{x}\)は頻出なので、状況によってはnp.exp(x * np.log(a))で高速化することも可能ですが、コードが複雑になったり、aが配列のときには高速化の恩恵がなくなるデメリットもあるため、採用するかどうかは状況次第でしょう。逆にaが配列であれば、どの方法でも変わらないということがわかったので、あまり気にしなくても良いということでもあります。
以上「NumPyレシピ | aのx乗(a^x, a**x)はどの方法が高速か?」でした!
またお会いしましょう!Ciao!
コメント