 データサイエンス
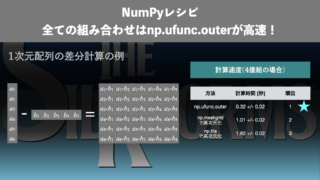
データサイエンス NumPyレシピ | 全ての組み合わせについての計算はnp.ufunc.outerで!
NumPy配列の要素同士の全ての組み合わせについて計算を行う方法を紹介します。例えば、2つの配列の要素同士の全ての組み合わせについて差分などです。np.ufunc.outer()を使う方法、np.meshgrid()やnp.tile()で2次元化する方法を比較します。
データサイエンス 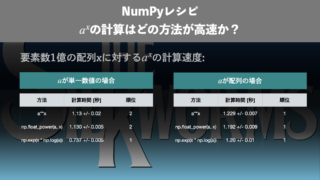 データサイエンス
データサイエンス  データサイエンス
データサイエンス 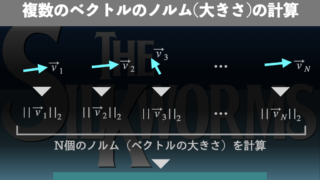 データサイエンス
データサイエンス  データサイエンス
データサイエンス 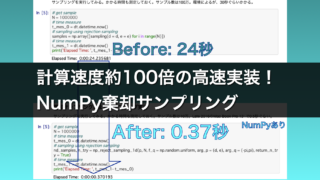 データサイエンス
データサイエンス