 データサイエンス
データサイエンス Matplotlib | Python作図での軸のスケール設定の必要性(Python軸スケール 1. 知識編)
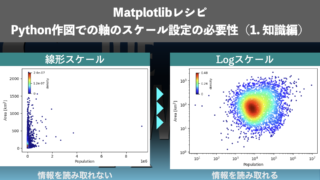
作図において軸のスケールを設定する必要性についてお話します!データによっては線形スケールではなくLogスケールなどに設定する必要があります。今回は線形、Log、Symlogスケールを使うべき場面を例をあげて解説します!
データサイエンス  データサイエンス
データサイエンス  データサイエンス
データサイエンス  データサイエンス
データサイエンス 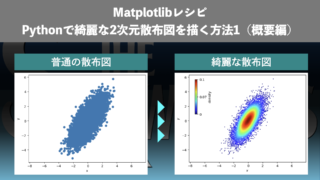 データサイエンス
データサイエンス 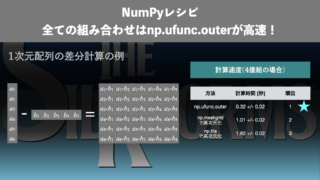 データサイエンス
データサイエンス 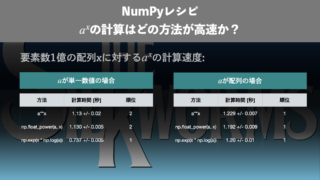 データサイエンス
データサイエンス  データサイエンス
データサイエンス 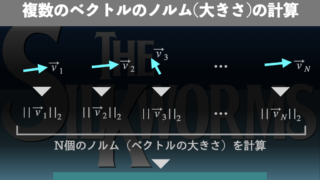 データサイエンス
データサイエンス  データサイエンス
データサイエンス