


みなさんこんにちは!このブログでは主に
の4つのトピックについて発信しています。
今回の記事では時系列データの分析について扱います!
これまでの記事では、時系列データの分析における「偽物の相関」の危険性↗や、定常性の確認↗、トレンドや季節性を含む非定常性の考え方↗、差分・トレンド除去・季節調整といった定常化の方法↗、そして実データの定常化↗について学んできました。さらに前回↗は、定常化した系列に対して ARIMA や SARIMA を適用し、単変量時系列モデルの比較を行いました。
今回は、複数の時系列データの関係を同時に扱う多変量時系列モデル VAR(Vector AutoRegression)を取り上げます。というのも、実務で時系列データを見ていると、売上と広告費、GDPと消費や金利のように、1本の系列だけでは捉えきれない関係が気になる場面があるからです。そこで本記事では、PythonでVARを実装しながら、時系列データ同士の影響関係を見たいときに、どのような場面でVARを使うと自然なのかを整理していきます。
この記事を読むことで、
- 単変量モデルでは不十分になるのはどのような場面か
- VAR とはどのような考え方のモデルなのか
- 時系列データ同士の関係を見たいときに、実務でどう判断すればよいのか
が理解できるはずです。
「時系列データを1本ずつ見ているけれど、本当は複数系列の関係も見たほうがよいのでは?」と感じたことがある方は、ぜひ最後まで読んでみてください。
- Abstract | VARは「複数の時系列データを同時に見る」ための基本モデル
- Introduction | 多変量時系列モデル
- Background | なぜ単変量モデルでは不十分になるのか
- Data | 複数の時系列データを準備する
- Method | VARモデルの考え方と分析手順
- Results | PythonでVARを実装する
- Discussion | どのようなときにVARを使うべきか
- Conclusion | VARは「複数系列の関係」を見るための基本モデル
- References | Pythonコードの全文
- 時系列分析シリーズ
Abstract | VARは「複数の時系列データを同時に見る」ための基本モデル
実務で時系列データを扱っていると、売上と広告費、GDPと消費や金利のように、複数の系列が互いに関係していそうで、1本の系列だけを見ていてよいのか迷う場面があります。こうしたときに有力な選択肢となるのが、多変量時系列モデル VAR(Vector AutoRegression)です。VARは、複数の時系列データを同時に扱い、それぞれの系列を自分自身の過去だけでなく他の系列の過去も使って表現できるモデルです。複数の時系列データが互いに影響し合う可能性を考えるには、多変量時系列モデルが必要になります。
本記事では、多変量時系列モデルの代表である VAR を取り上げます。VAR は、ある系列の現在値を、その系列自身の過去だけでなく、他の系列の過去も使って説明するモデルです。これにより、複数系列の関係を表現しながら、将来予測を行うことができます。
具体的には、複数の時系列データに対して Python で VAR モデルを適用し、
- 各系列の定常性の確認
- VAR の推定と予測
- 単変量モデルとの違い
- どのような場面で VAR を使うべきか
を順番に整理します。
結果として、VAR は「複数の時系列データの関係そのものを見たいとき」に有効な基本モデルである一方で、単に複数系列を入れればよいわけではなく、各系列の定常性や変数選択を含めて慎重に扱う必要があることを確認します。
Introduction | 多変量時系列モデル
第6回までの記事では、時系列データにおける非定常性をどのように見分け、どのように扱うか、そして定常化した系列に対してどのように単変量モデルを適用するかを見てきました。具体的には、
- 第1回:ランダムウォークが生む偽相関↗
- 第2回:ADF検定による定常性の確認↗
- 第3回:トレンドや季節性がある場合の考え方↗
- 第4回:差分、トレンド除去、季節調整といった定常化手法↗
- 第5回:株価・GDP・売上データに対する定常化手法の適用↗
- 第6回:ARIMA・SARIMAによる単変量時系列モデルの比較↗
を順番に整理してきました。ここまでで、非定常な系列をそのまま扱うのは危険であり、まず系列の性質を見極めて整える必要がある こと、そして 整えた系列はモデル化してはじめて予測や構造理解に使える ことが見えてきたと思います。
単変量モデルが自然な場面
時系列データをモデル化するうえで、まず基本となるのが単変量時系列モデルです。
単変量モデルでは、1本の系列だけに注目し、その系列自身の過去の値や過去の誤差、季節的な繰り返しを使って現在や未来の値を表現します。
この考え方は、対象となる系列の動きが主にその系列自身の履歴で説明できるときに自然です。実際、第6回↗で扱った ARIMA や SARIMA は、そのような単変量時系列モデルの代表例でした。
単変量モデルでは捉えきれない場面
ただし、実務で時系列データを扱っていると、1本の系列だけを見ていてよいのか迷う場面があります。たとえば、売上は自分自身の過去だけでなく、広告費や価格の影響を受けるかもしれません。GDP も、消費や金利と関係しながら動いているかもしれません。このような場面では、対象系列を単独で見るよりも、複数の時系列データをまとめて扱うほうが自然 です。
つまりここで問いたいのは、
「この系列をどう予測するか」だけではなく、「複数の系列がどのように関係しているかをどう表現するか」
ということです。
VAR | 多変量時系列モデルの代表例
こうしたときに基本的な選択肢となるのが、多変量時系列モデルです。
その代表例が VAR(Vector AutoRegression)です。
VAR では、ある系列の現在値を、その系列自身の過去だけでなく、他の系列の過去も使って説明します。言い換えると、複数の系列を同時に扱い、それぞれが互いにどのような影響を受けながら動いているかを表現するモデル です。
単変量モデルが「1本の系列の自己依存構造」を捉えるモデルだとすれば、VAR は「複数系列の相互関係」を含めて捉えるモデルだと考えることができます。
VARで何を見たいのか
VAR を使う目的は、単に複数系列をまとめて入れることではありません。
大事なのは、複数の時系列データの関係を見たいのかどうか です。
たとえば、
- 他の系列の情報を入れることで予測を改善したい
- 系列同士が時間差をもって影響し合っている可能性を見たい
- 1本の系列だけでは見えない構造を整理したい
といった場面では、VAR を考える意味があります。
今回の記事では、多変量時系列モデルの代表である VAR を取り上げ、どのようなときに単変量モデルではなく多変量モデルを考えるべきか、VAR は何をしているモデルなのか、そして実務でどのような判断軸を持てばよいのかを整理します。なお、今回は VAR の基本に絞って扱い、発展的な話題には立ち入りません。
Background | なぜ単変量モデルでは不十分になるのか
ここでは、なぜ単変量モデルだけでは扱いきれない場面があるのかを整理したうえで、VAR がどのような考え方のモデルなのかを確認します。ポイントは、
- 1本の時系列データだけでは捉えきれない関係があること、
- そして 複数の時系列データを同時に扱うには、そのためのモデルが必要になること
です。あわせて、ARIMA / SARIMA との違いや、VAR を使う前に確認したい前提条件も整理します。
単変量モデルでは捉えにくい関係
単変量時系列モデルは、1本の系列の過去の情報から、その系列の現在や未来を表現するモデルです。この考え方は、対象系列の動きが主にその系列自身の履歴で決まるときには自然です。
しかし、実務で扱う時系列データには、他の系列の影響を受けながら動くものが少なくありません。たとえば、売上は過去の売上だけでなく、広告費や価格、景気の影響を受けるかもしれません。また、GDP は消費や投資、金利などと関係しながら動いている可能性があります。
このような場合、1本の系列だけを切り出してモデル化すると、対象系列の動きの一部しか見えていないかもしれません。
つまり、「その系列自身の過去」だけでは不十分で、「他の系列の過去」もあわせて見たほうがよい場面 があるということです。
VARとは何をしているモデルなのか
このような場面で使われる基本的な多変量時系列モデルが、VAR(Vector AutoRegression)です。VAR では、ある系列の現在値を、その系列自身の過去だけでなく、他の系列の過去も使って説明します。たとえば、売上を予測するときに、過去の売上だけでなく、過去の広告費も使う、というイメージです。
さらに VAR では、売上だけを説明するのではなく、広告費のほうもまた、過去の広告費や過去の売上を使って説明することもできます。
このように、複数の系列を同時に扱い、各系列が他の系列の過去とどのように関係しているかを表現できる のが VAR の特徴です。
ただし、ここで重要なのは、VAR が常に双方向の影響を前提とするわけではないということです。
モデルの形としては複数の系列の関係を同時に扱えますが、実際には一方向の影響だけが強く現れることもあります。したがって、VAR は 「系列間の関係を扱える枠組み」 と捉えるのが自然です。
VARでできること
VAR を使うことで、複数の時系列データの関係を1つの枠組みの中で扱うことができます。
まず、系列間の影響を表現できます。ある系列が、他の系列の過去の値とどのように関係しているかをモデルに入れられるため、1本の系列だけでは捉えにくい構造 を見やすくなります。
また、系列間の関係を踏まえて、系列を将来予測したり、複数系列を同時に将来予測したりすることもできます。売上だけを予測するのではなく、売上と広告費、あるいは GDP と消費をまとめて予測する、といった使い方が可能です。
つまり VAR は、単に「説明変数を増やす」ためのものではなく、時系列データ同士の関係そのものをモデル化するための方法 だといえます。
ARIMA / SARIMA と VAR の違い
ここで、前回扱った ARIMA / SARIMA との違いを整理しておきます。
ARIMA や SARIMA は、1本の系列に注目する単変量モデルです。過去の値や誤差、季節性を使って、その系列の動きを表現します。したがって、対象系列の内部構造を丁寧に捉えたいときには非常に有力です。
一方、VAR は複数の系列を同時に扱う多変量モデルです。対象となる系列だけでなく、他の系列との関係も含めて表現したいときに向いています。
したがって、どちらが優れているというよりも、何を知りたいのか で使い分けるべきです。
- 1本の系列の動きを中心に見たいなら ARIMA / SARIMA
- 複数系列の関係まで含めて見たいなら VAR
という整理になります。
VARを使う前に確認したい前提条件
ただし、VAR は複数系列を扱えるからといって、いつでもそのまま使えるわけではありません。
重要なのは、各系列が定常であること です。これは単変量モデルのときと同じで、非定常な系列をそのまま使うと、見かけ上の関係を拾ってしまうおそれがあります。したがって、VAR を使う前にも、各系列について定常性を確認し、必要であれば差分などによって整える必要があります。
また、系列を増やしすぎると、推定すべきパラメータが急に増えてしまいます。
そのため、関係がありそうだからといって何でも入れるのではなく、本当に一緒に扱う意味がある系列かどうか を考えることも大切です。
つまり VAR は、複数系列の関係を見たいときの強力な基本モデルですが、前提確認なしに使うものではありません。単変量モデルと同じく、まずは系列の性質を見極めたうえで適用する必要があります。
Data | 複数の時系列データを準備する
ここでは、VAR を適用するために使用するデータを確認します。今回のポイントは、複数の時系列データを同じ時間軸でそろえたうえで、系列間の関係を見にいける題材を選ぶことです。第5回・第6回と同様に、本記事でも FRED からデータを取得します。今回使用する 3 系列はいずれも FRED から四半期データとして取得できます。
今回使用するデータ | 米国のマクロ経済指標
今回の実証では、米国のマクロ経済データとして以下の 3 系列を用います。
GDPC1:Real Gross Domestic Product(実質GDP)PCECC96:Real Personal Consumption Expenditures(実質個人消費支出)GPDIC1:Real Gross Private Domestic Investment(実質民間国内総投資)
これらはいずれも FRED 上で公開されており、出所は米国経済分析局(BEA)、頻度は四半期です。3 系列とも Seasonally Adjusted Annual Rate で公表されており、これは季節調整を施した四半期値を年率換算したものです。また、単位は Billions of Chained 2017 Dollars で、これは2017年基準の実質価格を10億ドル単位で表したものです。つまり、物価変動の影響を除いた水準です。
なぜこのデータがVARに向いているのか
この 3 系列を選ぶ理由は、どれも単独で動くのではなく、景気循環の中で関係しながら動くと考えやすいからです。GDP、消費、投資はマクロ経済の中心的な系列であり、1 本ずつ別々に見るよりも、まとめてモデル化することが妥当な題材です。また、3 系列はいずれも四半期データなので、同じタイミングで系列をそろえて扱いやすいという利点もあります。系列間の関係を考える VAR では、データの頻度を揃えておく必要があります。
データの前処理 | VARに適用できる形に整える
VAR をそのまま適用するのではなく、まず各系列の性質を確認し、必要な前処理を行います。ここでは、水準系列の確認と定常性の確認を順に行います。第5回で行った「系列を整える」作業を今回も実施します。
水準系列をプロットして特徴を確認する
最初に、GDPC1、PCECC96、GPDIC1 を水準のまま時系列プロットで確認します。ここで見たいのは、
- 長期的なトレンドがあるか
- 変動幅が時期によって変わっていないか
- 3 系列が似たタイミングで動いていそうか
という点です。今回使う 3 系列はいずれも実質の水準系列なので、まずはそのまま可視化し、その後に VAR に適した形へ整えていきます。
定常性を確認し、必要に応じて変換する
VAR を使う前に重要なのが、各系列の定常性を確認することです。GDP、消費、投資のようなマクロ系列は、水準のままではトレンドを含みやすく、そのままでは VAR の入力として使いにくいことがあります。そのため本記事では、ADF 検定で各系列の定常性を確認し、必要に応じて対数差分をとります。最終的に、変換後の系列に VAR を適用します。
Method | VARモデルの考え方と分析手順
ここでは、今回の分析をどのような手順で進めるかを整理します。VAR は複数の時系列データを同時に扱うモデルですが、やること自体は極端に複雑ではありません。基本的には、各系列を整えたうえで、ラグ次数を決めてモデルを推定し、将来予測と評価を行うという流れです。本記事では、VAR の数学的な詳細には立ち入らず、Python で再現できる実装手順と、実務で押さえたい判断ポイントに絞って進めます。
分析の全体フロー
今回の分析は、次の流れで進めます。
- FRED から
GDPC1、PCECC96、GPDIC1を取得する - 水準系列を可視化し、系列の特徴を確認する
- ADF 検定で定常性を確認する
- 必要に応じて対数差分をとる
- 学習用データと評価用データに分割する
- ラグ次数を選び、VAR モデルを推定する
- 将来予測を行う
- 実測値と予測値を比較し、予測誤差を確認する
第5回では、系列をそのまま扱わず、まず性質を確認してから変換を行いました。今回も同様に、VAR を当てる前に系列を整えることを前提にします。そのうえで、第6回と同じく、学習用データと評価用データを分けて予測性能を確認します。
VARモデルの基本的な考え方
VAR では、複数の系列をまとめて1つのベクトルとして扱います。
たとえば、GDP、消費、投資の3系列をまとめて \( \boldsymbol{y}_{t} \) と書くと、VAR(\( p \)) は次のように表せます。
$$
\boldsymbol{y}_{t} = \boldsymbol{c} + \boldsymbol{A}_{1} \boldsymbol{y}_{t-1} + \boldsymbol{A}_{2} \boldsymbol{y}_{t-2} + \cdots + \boldsymbol{A}_{p} \boldsymbol{y}_{t-p} + \boldsymbol{u}_{t}
$$
ここで、
- \( \boldsymbol{y}_{t} \) は時点 \( t \) の複数系列の値(縦ベクトル)
- \( \boldsymbol{c} \) は定数項(縦ベクトル)
- \( \boldsymbol{A}_{1}, \boldsymbol{A}_{2}, \cdots, \boldsymbol{A}_{p} \) はラグごとの係数行列
- \( \boldsymbol{u}_{t} \) は誤差項(縦ベクトル)
です。
重要なのは、各系列が自分自身の過去だけでなく、他の系列の過去からも説明されるという点です。単変量の AR モデルでは、1本の系列の現在値をその系列自身の過去で説明します。これに対して VAR では、複数系列の過去をまとめて使うことで、系列間の関係をモデルに取り込みます。
今回の記事では、この式を厳密に展開することよりも、「複数系列の過去を使って、各系列を同時にモデル化する」という考え方を押さえることを重視します。
数式の補足 | 今回の例におけるVARの定式化
今回の例では、\(t\)時点におけるGDP、消費、投資をそれぞれ\(y_{\mathrm{GDP}, t}, y_{\mathrm{Cons}, t}, y_{\mathrm{Inv}, t} \)と書くと、\( \boldsymbol{y}_{t} \) は
$$
\boldsymbol{y}_{t} =
\begin{pmatrix}
y_{\mathrm{GDP}, t} \\
y_{\mathrm{Cons}, t} \\
y_{\mathrm{Inv}, t}
\end{pmatrix}
$$
のような縦ベクトルになります。
各\( \boldsymbol{A}_{i} \)は、3 系列どうしの影響を並べた\( 3 \times 3 \)の係数行列です。
たとえば VAR(1)は、
$$
\begin{pmatrix}
y_{\mathrm{GDP}, t} \\
y_{\mathrm{Cons}, t} \\
y_{\mathrm{Inv}, t}
\end{pmatrix}
=
\begin{pmatrix}
c_1 \\
c_2 \\
c_3
\end{pmatrix}
+
\begin{pmatrix}
a_{11, 1} & a_{12, 1} & a_{13, 1} \\
a_{21, 1} & a_{22, 1} & a_{23, 1} \\
a_{31, 1} & a_{32, 1} & a_{33, 1}
\end{pmatrix}
\begin{pmatrix}
y_{\mathrm{GDP}, t-1} \\
y_{\mathrm{Cons}, t-1} \\
y_{\mathrm{Inv}, t-1}
\end{pmatrix}
+
\begin{pmatrix}
u_{1, t} \\
u_{2, t} \\
u_{3, t}
\end{pmatrix}
$$
となります。
これを成分ごとに書くと、
$$
\begin{align}
y_{\mathrm{GDP}, t}
&=
c_1
+ a_{11, 1} \ y_{\mathrm{GDP}, t-1}
+ a_{12, 1} \ y_{\mathrm{Cons}, t-1}
+ a_{13, 1} \ y_{\mathrm{Inv}, t-1}
+ u_{1, t} \\
y_{\mathrm{Cons}, t}
&=
c_2
+ a_{21, 1} \ y_{\mathrm{GDP}, t-1}
+ a_{22, 1} \ y_{\mathrm{Cons}, t-1}
+ a_{23, 1} \ y_{\mathrm{Inv}, t-1}
+ u_{2, t} \\
y_{\mathrm{Inv}, t}
&=
c_3
+ a_{31, 1} \ y_{\mathrm{GDP}, t-1}
+ a_{32, 1} \ y_{\mathrm{Cons}, t-1}
+ a_{33, 1} \ y_{\mathrm{Inv}, t-1}
+ u_{3, t}
\end{align}
です。つまり、GDP は過去の GDP だけでなく、過去の消費や投資でも説明されます。消費や投資についても同様です。
ラグ次数をどう決めるか
VAR では、何期前までの情報を使うかを表すラグ次数\( p \)を決める必要があります。
ラグ次数が小さすぎると、必要な情報を取りこぼすかもしれません。逆に大きすぎると、パラメータが増えすぎて不安定になりやすくなります。
そのため本記事では、複数の候補に対して情報量基準を確認し、ラグ次数を選びます。代表的には、
- AIC
- BIC
- HQIC
などが使われます。
ただし、情報量基準だけで機械的に決めればよいわけではありません。
特に VAR は、系列数が増えると係数の数が急に増えます。したがって、サンプルサイズに対してラグを大きくしすぎていないかもあわせて確認する必要があります。
本記事では、まず情報量基準を参考に候補を絞り、そのうえで過剰に複雑なモデルになっていないかを確認しながらラグ次数を決めます。
学習用データと評価用データへの分割
モデルを作ったあとは、そのモデルがどの程度うまく予測できるかを確認する必要があります。
そのため、今回もデータを 学習用データ と 評価用データ に分けます。
ここで重要なのは、時系列データではランダムにシャッフルして分割しないことです。
未来の情報が過去のモデルに混ざると、評価が不適切になります。したがって、時系列の順序を保ったまま、前半を学習用、後半を評価用 として分けます。
今回の記事では、変換後の系列を時系列順に並べたうえで、直近の一定期間を評価用データとして取り分けます。こうすることで、学習済みモデルが未知の将来区間をどの程度予測できるかを確認できます。
予測と評価の進め方
ラグ次数を決めて VAR を推定したら、評価用データの期間に対して将来予測を行います。
そのうえで、実測値と予測値を比較します。
今回の評価では、主に次の2点を確認します。
- 時系列プロットによる比較
実測値と予測値を重ね描きし、系列の動きをどの程度追えているかを確認します。 - 予測誤差の確認
各系列について、MAE や RMSE などの指標を計算し、予測のずれを定量的に見ます。
ただし、本記事の主眼は予測精度の厳密な競争ではありません。
重要なのは、複数系列を同時に扱うことで、単変量モデルとは異なる見方ができるか を確認することです。そのため、評価は必要最低限にとどめつつ、系列間の関係を踏まえたモデル化がどのように機能するかを見ることを重視します。
今回のMethodで押さえたい点
以上をまとめると、今回の Method で押さえたい点は次の3つです。
- VAR の前に、各系列を定常化しておくこと
- ラグ次数は情報量基準とモデルの複雑さの両方を見て決めること
- 予測精度だけでなく、複数系列を同時に扱う意義を確認すること
次の Results では、この方針に沿って Python で実際に VAR を実装し、予測結果を確認していきます。
Results | PythonでVARを実装する
ここでは、FRED から取得した GDP・消費・投資の 3 系列に対して、実際に VAR モデルを適用します。分析の流れは、
- 水準系列の確認
- 定常化
- 学習用データと評価用データへの分割
- ラグ次数の選択
- VAR の推定
- 将来予測と評価
です。第5回↗で行った「系列を整える」作業を踏まえつつ、今回はその先として、複数系列を同時にモデル化したときにどのような予測が得られるかを確認します。
必要なライブラリを準備する
今回の実装に必要なライブラリをインポートしておきます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas_datareader.data import DataReader
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.api import VAR
from sklearn.metrics import mean_absolute_error, mean_squared_errorGDP・消費・投資のデータ取得
まずは米国のGDP・消費・投資のデータを取得し、プロットして推移を確認してみましょう。
FREDからデータをダウンロード
まず、FRED から GDPC1、PCECC96、GPDIC1 を取得し、それぞれを GDP、Consumption、Investment として扱います。期間は 1960 年から 2025 年初までです。
# Set date range
start = "1960-01-01"
end = "2025-01-01"
# Define FRED series
series = ["GDPC1", "PCECC96", "GPDIC1"]
# Download data from FRED
df = DataReader(series, "fred", start, end)
# Drop missing values
df = df.dropna()
# Rename columns for readability
df.columns = ["GDP", "Consumption", "Investment"]
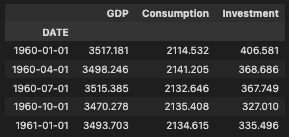
df.head()上記を実行すると、下図1のようにデータフレームの一部が表示されます。

データをプロットして確認
ダウンロードしたデータをプロットし、それぞれの推移を確認します。
fig, ax = plt.subplots(figsize=(10, 6))
df.plot(ax=ax)
ax.set_title("Macroeconomic series in levels")
ax.set_ylabel("Billions of chained 2017 dollars")
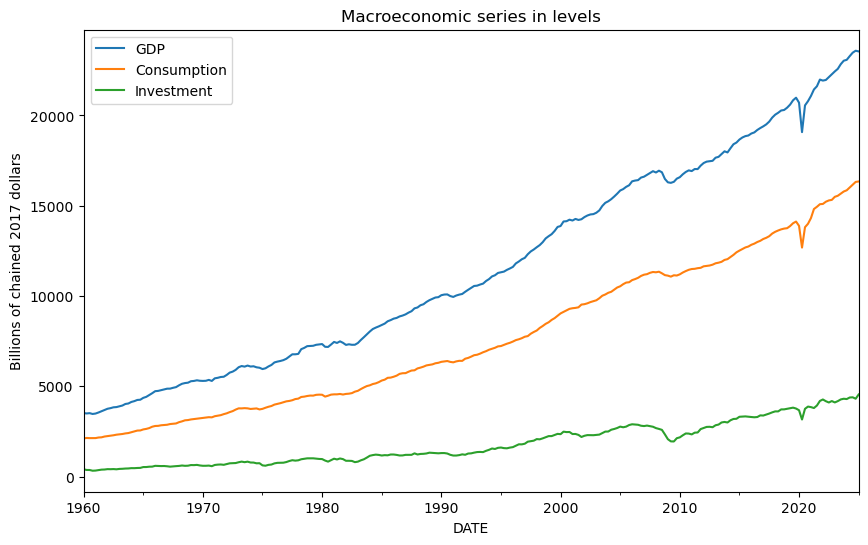
plt.show()上記を実行すると、下図2が表示されます。

定常化の必要性
図2のように水準系列をプロットすると、GDP・消費・投資のいずれも長期的な上昇トレンドを持っていることがわかります。特に GDP と消費は比較的なめらかに増加しており、投資はそれらに比べて変動が大きくなっています。したがって、これらの系列をそのまま VAR に入力するのは適切ではありません。まずは定常性を確認し、必要な変換を行う必要があります。
データの前処理 | 定常性確認と対数差分化
データの前処理として下記の作業を行います。
- ADF検定による定常性の確認
- 必要に応じて対数差分をとる
ADF検定による定常性の確認 | 3系列とも非定常
まずは3つのデータについてADF検定を行います。対数差分化してからまたADF検定を行うので、関数として処理をまとめておきます。
# function for ADF test
def adf_test(series, name=""):
result = adfuller(series.dropna())
print(f"ADF test for {name}")
print(f" test statistic: {result[0]:.4f}")
print(f" p-value : {result[1]:.4f}")
print(f" used lags : {result[2]}")
print(f" nobs : {result[3]}")
print()各系列にADF検定をかけます。
# ADF test for original series
for col in df.columns:
adf_test(df[col], name=col)上記を実行した結果は下記のようになりました。
ADF test for GDP
test statistic: 2.6502
p-value : 0.9991
used lags : 1
nobs : 259
ADF test for Consumption
test statistic: 3.1971
p-value : 1.0000
used lags : 1
nobs : 259
ADF test for Investment
test statistic: 1.4448
p-value : 0.9973
used lags : 0
nobs : 260各水準系列に対して ADF 検定を行った結果は以下の通りです。
- GDP:検定統計量 2.6502、p 値 0.9991
- Consumption:検定統計量 3.1971、p 値 1.0000
- Investment:検定統計量 1.4448、p 値 0.9973
いずれも p 値が非常に大きく、単位根があるという帰無仮説を棄却できません。つまり、3 系列とも水準のままでは非定常と判断されます。これはプロットから見えた強いトレンドとも整合的です。
対数差分化 | 定常性確保のための処理
定常性を確保するため、3系列すべてに対して自然対数をとり、その一次差分を計算します。これは、実質水準系列を成長率に近い形へ変換する操作です。
# get log-diff
df_logdiff = np.log(df).diff().dropna()
# check records
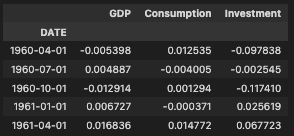
df_logdiff.head()上記を実行すると下図3のようにデータフレームの一部が表示されます。

対数差分系列の定常性の確認
対数差分系列についてADF検定を行い、定常性を確認します。さきほど作成した関数`adf_test`を使います。
# ADF test for log-diff series
for col in df_logdiff.columns:
adf_test(df_logdiff[col], name=col)上記を実行した結果は以下のようになります。
ADF test for GDP
test statistic: -15.4210
p-value : 0.0000
used lags : 0
nobs : 259
ADF test for Consumption
test statistic: -7.9083
p-value : 0.0000
used lags : 2
nobs : 257
ADF test for Investment
test statistic: -14.1358
p-value : 0.0000
used lags : 0
nobs : 259対数差分系列のプロット
対数差分に変換した系列についても時系列でプロットし様子を確認します。
fig, ax = plt.subplots(figsize=(10, 6))
df_logdiff.plot(ax=ax)
ax.set_title("Log-differenced macroeconomic series")
ax.set_ylabel("Log difference")
plt.show()実行結果は下図4です。

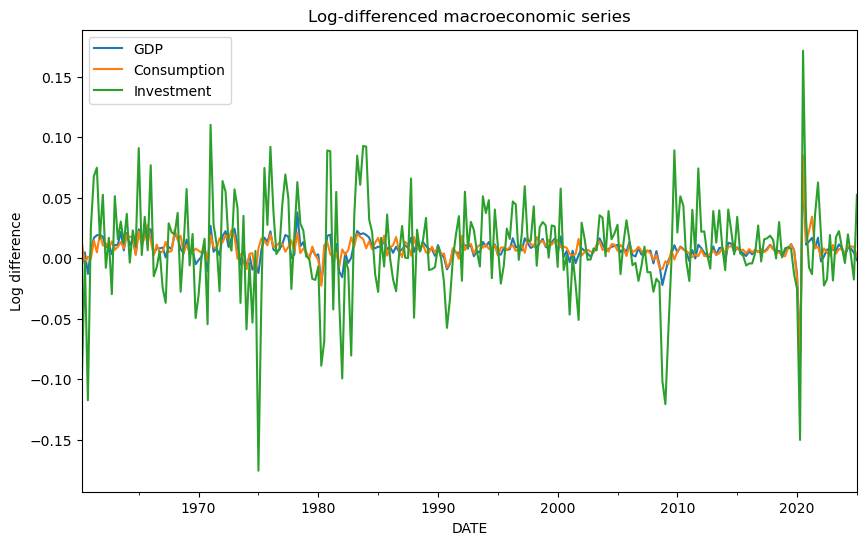
対数差分化による定常化のまとめ
対数差分に変換後の系列に対して ADF 検定を行った結果は以下の通りです。
- GDP:検定統計量 -15.4210、p 値 0.0000
- Consumption:検定統計量 -7.9083、p 値 0.0000
- Investment:検定統計量 -14.1358、p 値 0.0000
今度はいずれも p 値が十分に小さく、対数差分後の 3 系列は定常とみなせることがわかります。プロットでも、各系列はゼロ近傍を中心に上下しており、水準系列で見られた長期トレンドは取り除かれています。また、投資系列は GDP や消費に比べて変動が大きく、変換後もなおボラティリティの高い系列であることが見て取れます。
学習用データと評価用データに分割
定常化した3系列を学習用データと評価用データに分割します。ここでは直近 20 期を評価用に取り、残りを学習用とします。時系列データでは、ランダムにシャッフルして分割するのではなく、時系列の順序を保ったまま過去で学習し、未来で評価する必要があります。今回もその原則に従って分割します。
n_test = 20
train = df_logdiff.iloc[:-n_test]
test = df_logdiff.iloc[-n_test:]
print("train shape:", train.shape)
print("test shape :", test.shape)実行結果は以下のとおりです。
train shape: (240, 3)
test shape : (20, 3)
VARモデルの推定
データの準備ができたので、VARモデルの推定を行います。VARモデルVAR\( p \)のラグ数\( p \)を決定し、学習データでモデルパラメータの推定をします。
最大ラグ数の設定
まず、最大でどこまでのラグを考慮するかを決めます。VARモデルのラグ数\( p \)は、AICやBICなどの情報基準量を使って、1から最大ラグ数までの間から決定することになります。最大ラグ数を所与としてVARモデルを当てはめ、AIC、BICなどの情報基準量を計算、表示します。
# get model
model = VAR(train)
# set max lag and get order
lag_order_results = model.select_order(maxlags=8)
print(lag_order_results.summary())上記を実行すると、以下の結果となります。
VAR Order Selection (* highlights the minimums)
=================================================
AIC BIC FPE HQIC
-------------------------------------------------
0 -28.24 -28.20 5.437e-13 -28.22
1 -28.58 -28.41* 3.856e-13 -28.51*
2 -28.59 -28.28 3.844e-13 -28.46
3 -28.63* -28.18 3.689e-13* -28.45
4 -28.62 -28.04 3.710e-13 -28.39
5 -28.62 -27.91 3.714e-13 -28.33
6 -28.59 -27.75 3.819e-13 -28.25
7 -28.57 -27.59 3.907e-13 -28.18
8 -28.58 -27.47 3.880e-13 -28.13
-------------------------------------------------最大ラグを 8 として情報量基準を比較した結果、AIC と FPE はラグ 3 を、BIC と HQIC はラグ 1 を支持しました。
モデル選択(ラグ選択)
今回は、AIC を基準にラグ 3 を採用します。したがって、以降では VAR(3) を用いて分析を進めます。
selected_lag = lag_order_results.selected_orders["aic"]
print("Selected lag by AIC:", selected_lag)上記の実行結果は以下です。
selected_lag = lag_order_results.selected_orders["aic"]
print("Selected lag by AIC:", selected_lag)AICによるラグ選択の結果は、系列間の関係を捉えるには 1 期前だけでは足りず、少なくとも数期分の履歴を入れたほうがよい可能性を示しています。一方で、ラグを増やしすぎるとパラメータ数が急増するため、ここでは AIC が最小となる 3 を採用するのが妥当です。
モデルパラメータの推定
選ばれたラグでVAR(3)のパラメータを推定します。学習データにモデルをフィットします。
var_result = model.fit(selected_lag)
print(var_result.summary())上記の実行結果は以下です。
Summary of Regression Results
==================================
Model: VAR
Method: OLS
Date: Tue, 21, Apr, 2026
Time: 05:29:12
--------------------------------------------------------------------
No. of Equations: 3.00000 BIC: -28.1313
Nobs: 237.000 HQIC: -28.3933
Log likelihood: 2406.71 FPE: 3.90990e-13
AIC: -28.5702 Det(Omega_mle): 3.45398e-13
--------------------------------------------------------------------
Results for equation GDP
=================================================================================
coefficient std. error t-stat prob
---------------------------------------------------------------------------------
const 0.002023 0.001002 2.018 0.044
L1.GDP -0.315139 0.153748 -2.050 0.040
L1.Consumption 0.689439 0.117568 5.864 0.000
L1.Investment 0.045390 0.026212 1.732 0.083
L2.GDP 0.055805 0.155790 0.358 0.720
L2.Consumption 0.213522 0.131557 1.623 0.105
L2.Investment -0.012542 0.026830 -0.467 0.640
L3.GDP -0.155100 0.154957 -1.001 0.317
L3.Consumption 0.132515 0.130392 1.016 0.309
L3.Investment 0.006306 0.025383 0.248 0.804
=================================================================================
Results for equation Consumption
=================================================================================
coefficient std. error t-stat prob
---------------------------------------------------------------------------------
const 0.004061 0.000885 4.590 0.000
L1.GDP -0.067252 0.135678 -0.496 0.620
L1.Consumption 0.230450 0.103750 2.221 0.026
L1.Investment 0.017349 0.023131 0.750 0.453
L2.GDP -0.048514 0.137481 -0.353 0.724
L2.Consumption 0.202650 0.116096 1.746 0.081
L2.Investment -0.000126 0.023677 -0.005 0.996
L3.GDP -0.305440 0.136746 -2.234 0.026
L3.Consumption 0.377834 0.115068 3.284 0.001
L3.Investment 0.039854 0.022400 1.779 0.075
=================================================================================
Results for equation Investment
=================================================================================
coefficient std. error t-stat prob
---------------------------------------------------------------------------------
const -0.007136 0.004588 -1.555 0.120
L1.GDP -2.203176 0.703580 -3.131 0.002
L1.Consumption 4.162357 0.538012 7.737 0.000
L1.Investment 0.381209 0.119951 3.178 0.001
L2.GDP 0.543045 0.712927 0.762 0.446
L2.Consumption 0.075997 0.602030 0.126 0.900
L2.Investment -0.078151 0.122778 -0.637 0.524
L3.GDP -0.681500 0.709115 -0.961 0.337
L3.Consumption -0.283740 0.596700 -0.476 0.634
L3.Investment 0.044694 0.116156 0.385 0.700
=================================================================================
Correlation matrix of residuals
GDP Consumption Investment
GDP 1.000000 0.630379 0.745443
Consumption 0.630379 1.000000 0.169347
Investment 0.745443 0.169347 1.000000これでVAR(3)の推定が完了しました。
モデルの評価
評価用データを使ってVAR(3)による予測結果を評価します。
- 評価期間における予測
- プロットして確認
- 予測誤差を確認
という手順で進めます。
評価期間における予測
まずは評価期間において、さきほど推定したVAR(3)を使って予測を行います。
# get train data in latest n_lag periods
lagged_values = train.values[-selected_lag:]
# get forecast
forecast = var_result.forecast(y=lagged_values, steps=n_test)
forecast_df = pd.DataFrame(
forecast,
index=test.index,
columns=test.columns
)
# see forecast
forecast_df.head()上記を実行すると、下図5のように予測結果の一部が表示されます。予測結果も対数差分系列の値です。

予測結果をプロットして確認
予測結果をプロットして確認します。実測値と予測値を重ねて比較します。
for col in test.columns:
fig, ax = plt.subplots(figsize=(10, 4))
train[col].plot(ax=ax, label="train")
test[col].plot(ax=ax, label="test")
forecast_df[col].plot(ax=ax, label="forecast")
ax.set_title(f"{col}: actual vs forecast")
ax.legend()
plt.show()実行結果は下図6、7、8です。

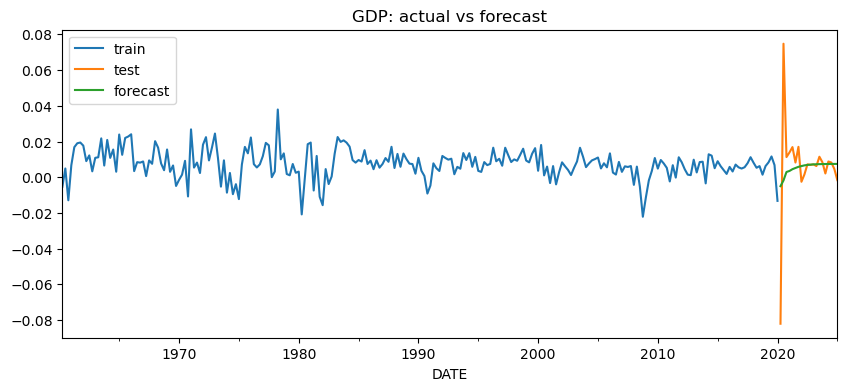

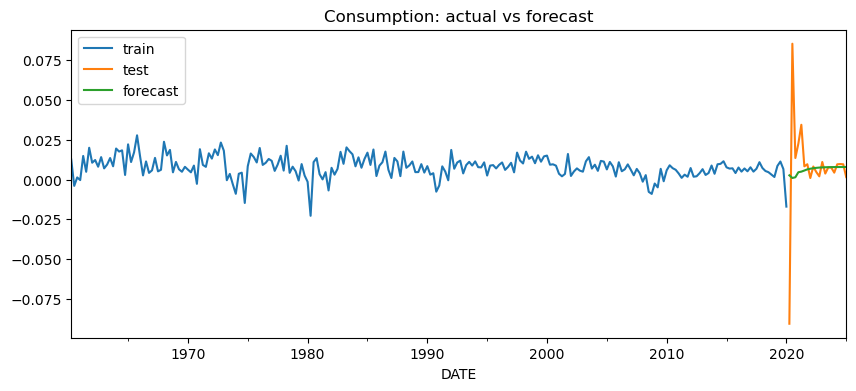
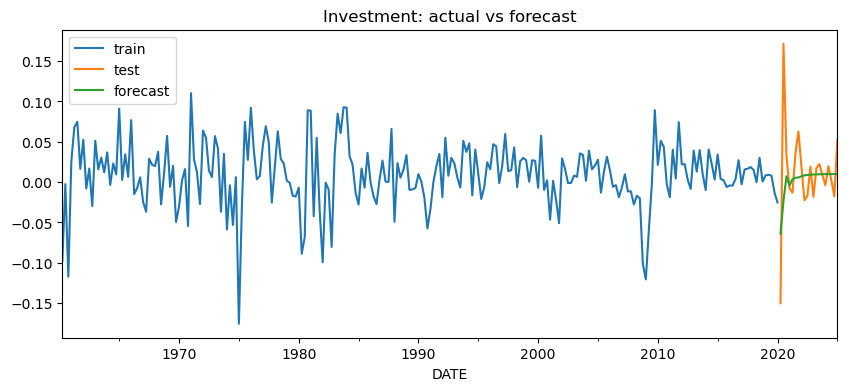
得られた予測を見ると、VAR(3) は GDP・消費・投資の 3 系列を同時に将来予測できています。これは単変量モデルとの大きな違いです。単変量モデルでは、各系列を別々に予測する必要がありますが、VAR では複数系列の過去をまとめて使いながら、それぞれの将来値を一貫した形で出力できます。
コロナ禍の影響とその後の推移の予測
図6から8を見ると、予測期間開始直後の大きな落ち込みは十分に予測できていないものの、その後の回復については大局的には予測ができていることがわかります。予測対象となる最初の時点は 2020 年 4 月であり、ちょうど新型コロナウイルス流行初期の大きな経済ショックが入る局面に当たります。
今回のVAR(3)モデルでは、評価期間冒頭のコロナ禍の急激な落ち込みと、その直後の大きな反動までは十分に捉えられていません。これは GDP、消費、投資のいずれにも共通しています。特に投資では変動が大きく、実測値の振れ幅に対して予測値はかなり滑らかです。
一方で、その後の推移を見ると、VAR(3) の予測は、大きなショックの後に各系列の成長率がゼロ近傍へ戻っていくという大まかな方向感を捉えています。GDP と消費では特にその傾向が見やすく、極端な乱高下を再現することはできなくても、ショック後の落ち着きどころはある程度追えているといえます。この背景には、コロナ禍での経済ショックからの立ち直りが、過去の経済ショックからの立ち直りと似たの推移であることがあります。
今回の VAR(3) は、突発的な巨大ショックそのものを当てるモデルというより、複数系列の関係を踏まえながら、その後の標準的な動きへ戻っていく過程を表現するモデルとして理解するのが適切です。
予測誤差の確認 | MAE・RMSE
最後に、各系列の予測誤差を MAE と RMSE で確認します。MAEは”Mean Absolute Error”で、予測値と実績値の差の絶対値の平均、RMSEは”Root Mean Squared Error”は予測値と実績値の差の2乗の平均の平方根です。どちらもモデルのハズレ具合を評価する指標ですが、MAEは外れ値の影響を受けにくく”モデルの全体的なハズレ具合”を評価するのに対し、RMSEは外れ値の影響を受けやすく”大きなハズレを重視”した評価となります。
さて、以下のように評価期間におけるMAEとRMSEを計算します。
metrics = []
for col in test.columns:
mae = mean_absolute_error(test[col], forecast_df[col])
rmse = np.sqrt(mean_squared_error(test[col], forecast_df[col]))
metrics.append([col, mae, rmse])
metrics_df = pd.DataFrame(metrics, columns=["series", "MAE", "RMSE"])
metrics_df実行結果は下図9です。

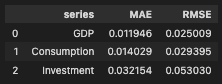
予測誤差の結果をまとめると以下の通りです。
- GDP:MAE = 0.011946、RMSE = 0.025009
- Consumption:MAE = 0.014029、RMSE = 0.029395
- Investment:MAE = 0.032154、RMSE = 0.053030
この結果から、投資系列の予測誤差が最も大きいことがわかります。これは、対数差分後のプロットでも見られたように、投資が GDP や消費よりも変動の大きい系列であることと整合的です。逆に、GDP と消費は比較的安定しており、誤差も投資より小さくなっています。
Results から確認できたこと
以上の結果から、今回の実証では次の点が確認できました。
- GDP・消費・投資の水準系列は、いずれも強いトレンドを持つ非定常系列である
- 対数差分をとることで、3 系列とも定常とみなせる形に整えられた
- 情報量基準に基づくラグ選択では、AIC により VAR(3) が選ばれた
- VAR により、GDP・消費・投資を同時に予測できた
- コロナ禍の急激なショック自体は捉えきれないが、その後の大きな方向感はある程度追えていた
- 予測誤差は投資で最も大きく、GDP と消費では比較的小さかった
このように、VAR は複数系列をまとめて扱うことで、単変量モデルとは異なる視点を与えてくれます。ただし、予測精度だけを見れば常に単変量モデルより優れるとは限らず、特に大きな外生ショックに対しては限界もあります。次の Discussion では、こうした結果を踏まえて、どのようなときに VAR を使うべきかを整理します。
Discussion | どのようなときにVARを使うべきか
ここまでの分析では、GDP・消費・投資という 3 系列を同時に扱うことで、単変量モデルとは異なる形で時系列データをモデル化できることが確認できました。一方で、VAR を使えば常に高精度な予測が得られるわけではなく、大きな外生ショックに対しては限界もあることが見えてきました。ここでは、今回の結果を踏まえて、VAR が有効になりやすい場面と、使う際に注意すべき点を整理します。
VARが有効なのは、系列間の関係そのものを見たいとき
今回の分析で最も重要なのは、GDP・消費・投資を別々に予測したのではなく、まとめてモデル化したという点です。VAR では、ある系列をその系列自身の過去だけでなく、他の系列の過去も使って説明できます。したがって、1 本の系列だけを見ていては捉えにくい関係を、モデルの中に入れることができます。
この特徴が生きるのは、たとえば次のような場面です。
- 売上を予測したいが、広告費や価格の動きも無視できない
- GDP の動きを見たいが、消費や投資との関係も含めて考えたい
- ある系列の予測だけでなく、複数系列の整合的な見通しを作りたい
このような場面では、単変量モデルよりも、VAR のような多変量モデルのほうが問題設定に合っています。重要なのは、「複数系列を使えるから VAR を選ぶ」のではなく、「系列間の関係を見たいから VAR を選ぶ」という順序です。
単変量モデルで十分な場面もある
一方で、すべての時系列問題に VAR が必要なわけではありません。対象となる系列の動きが主にその系列自身の履歴で説明できるのであれば、ARIMA や SARIMA のような単変量モデルで十分なこともあります。
たとえば、
- 予測対象が 1 系列だけでよい
- 他系列の情報を加えても改善が小さい
- 系列間の関係よりも、対象系列の自己依存や季節性のほうが支配的
といった場合には、単変量モデルのほうが扱いやすいことも少なくありません。
特に実務では、モデルの複雑さが上がるほど、前処理や保守、説明のコストも増えます。そのため、VAR が使えるかどうかだけでなく、VAR を使う必要があるかどうかを考えることが大切です。
今回の結果は、VARの強みと限界の両方を示している
今回の Results では、VAR(3) によって GDP・消費・投資を同時に予測できました。これは、単変量モデルにはない明確な強みです。複数系列の過去をまとめて使うことで、各系列を一貫した枠組みで扱うことができました。
その一方で、評価期間の冒頭にあるコロナ禍の急激な落ち込みと、その直後の反動は十分に捉えられませんでした。これは、VAR が過去の系列パターンをもとに将来を予測するモデルであり、過去に十分現れていない巨大ショックまでは表現しにくいことを示しています。
この点は重要です。VAR は系列間の関係を扱えるモデルですが、外生的な構造変化や突発的な制度変更、危機的イベントを直接説明するモデルではありません。したがって、今回のように大きなショックが含まれる局面では、VAR の予測をそのまま鵜呑みにするのではなく、「平常時の関係を表しているモデルなのか」「ショック後も同じ関係が維持されるのか」を別途考える必要があります。
VARを使う前には、系列を整える作業が欠かせない
今回の分析でも、水準系列のままでは 3 系列とも非定常でした。対数差分をとって初めて、VAR を適用できる形に整えることができました。これは、第5回までで見てきた内容と完全につながっています。
つまり、VAR は多変量モデルではありますが、前提条件の確認が不要になるわけではありません。むしろ、複数系列を同時に扱うぶん、各系列について定常性や変換方法を丁寧に確認する必要があります。
実務でありがちなのは、「関係がありそうな系列をとりあえず全部入れる」というやり方ですが、これは危険です。系列を増やすと推定すべきパラメータが急に増え、モデルは不安定になりやすくなります。したがって、VAR では
- その系列は本当に入れる意味があるか
- 各系列は適切に定常化されているか
- データ長に対して系列数やラグ数が大きすぎないか
を事前に確認する必要があります。
実務での判断軸は、「複数系列を入れる意味があるか」
実務で VAR を使うべきかどうかを考えるとき、最も重要なのは 「複数系列を同時に扱う意味があるか」 という問いです。
たとえば、売上だけを予測したいとしても、広告費や価格、景気指標を入れることで、予測や解釈が明らかに改善するなら、多変量モデルを考える価値があります。逆に、他系列を入れても改善が小さい、あるいは説明や運用が難しくなるだけなら、単変量モデルのほうが適切かもしれません。
したがって、実務での判断軸は次のように整理できます。
- 対象系列は、他系列の影響を強く受けていそうか
- その関係をモデルに入れることで、予測や解釈が改善しそうか
- 追加する系列は、頻度・期間・前処理を揃えて安定的に扱えるか
- モデルの複雑さに見合うだけのデータ量と運用体制があるか
このように考えると、VAR は「上級だから使うモデル」ではありません。複数系列の関係を見に行く必要があるときに選ぶモデルです。
Conclusion | VARは「複数系列の関係」を見るための基本モデル
本記事では、多変量時系列モデルの代表である VAR を取り上げ、GDP・消費・投資の 3 系列に適用しました。VAR の特徴は、ある系列をその系列自身の過去だけでなく、他の系列の過去も使って説明できることにあります。これにより、複数の時系列データを関係を持ったものとして同時に扱うことができます。
一方で、VAR は単変量モデルの上位互換ではありません。1 本の系列の動きを中心に見たいなら ARIMA / SARIMA が適している場合もありますし、複数系列の関係を見たいときには VAR が有力になります。重要なのは、モデル名ではなく、何を知りたいのかに応じて使い分けることです。
また、今回の分析でも、水準系列のままでは 3 系列とも非定常であり、そのまま VAR を適用することはできませんでした。多変量モデルであっても、系列を整えてから使うという基本は変わりません。
つまり VAR は、複数の時系列データの関係そのものを見たいときに有効な基本モデルです。時系列データを 1 本ずつ見るだけで十分なのか、それとも複数系列をまとめて見るべきなのか。その判断が必要になったとき、VAR は重要な選択肢になります。
次回予告
今回は、VAR を使って複数の時系列データを同時にモデル化する基本を確認しました。次回は、ここまで学んできた定常化、単変量モデル、多変量モデルを踏まえて、実務でよくある課題と解決策を整理します。前処理で迷いやすい点、モデル選択で陥りやすい落とし穴、結果の解釈で注意すべき点をまとめながら、実務で時系列モデルを使うときの判断軸を確認していきます。
References | Pythonコードの全文
今回の記事で書いたPythonコード(Jupyter Notebook)の全文は以下です。ご参考にどうぞ!